今天小编就为大家带来一篇介绍复述中管道的文章。小编觉得挺实用的,为此分享给大家做个参考。一起跟随小编过来看看吧。
一、管道出现的背景:
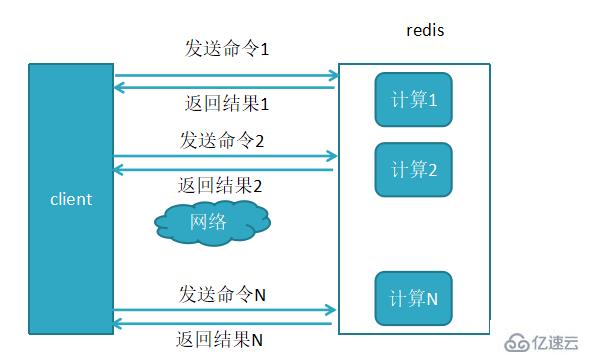
复述,执行一条命令有四个过程:发送命令,命令排队,命令执行,返回结果;
这个过程称为往返时间(简称RTT,往返时间),mget mset有效节约了RTT,但大部分命令(如hgetall,并没有mhgetall)不支持批量操作,需要消耗N次RTT,这个时候需要管道来解决这个问题。
二、管路的性能
1,未使用管道执行N条命令
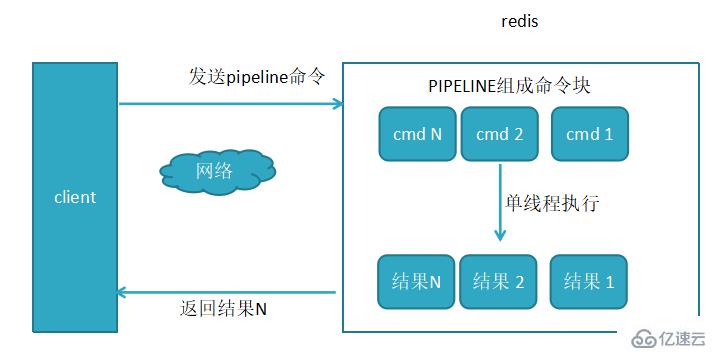
2,使用了管道执行N条命令
3,两者性能对比
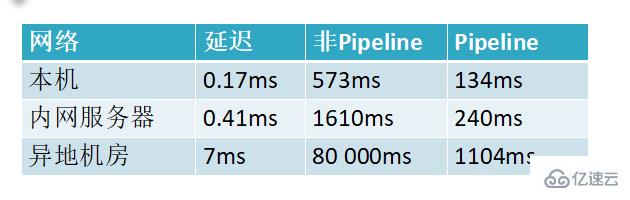
小结:这是一组统计数据出来的数据,使用管道执行速度比逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体能越明显。
下面贴出测试代码分析两者的性能差异:
@test
公共空间pipeCompare () {
能复述=新能(“192.168.1.111", 6379);
redis.auth(“12345678“);//授权密码对应redis.conf的requirepass密码
String> Map<字符串;data=https://www.yisu.com/zixun/new HashMap <字符串,字符串> ();
redis.select(8);//使用第8个库
redis.flushDB();//清空第8个库所有数据//hmset
长开始=System.currentTimeMillis ();//直接hmset
for (int i=0;我<10000;我+ +){
data.clear ();//清空地图
数据。把(k_ +我,“v_”+ i);
复述。hmset (“key_”+ i,数据);//循环执行10000条数据插入复述
}
长债=System.currentTimeMillis ();
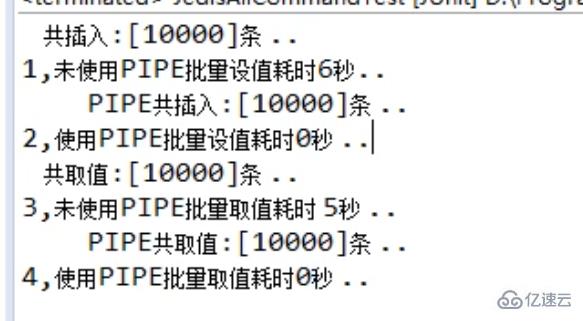
system . out。println(“共插入:[" + redis.dbSize() + "]条. .”);
system . out。println(“1,未使用管批量设值耗时”+(结束-开始)/1000 +“秒…”);
redis.select (8);
redis.flushDB ();//使hmset用管道
管线管=redis.pipelined ();
开始=System.currentTimeMillis ();//for (int i=0;我<10000;我+ +){
data.clear ();
数据。把(k_ +我,“v_”+ i);
管道。hmset (“key_”+ i,数据);//将值封装到管对象,此时并未执行,还停留在客户端
}
pipe.sync ();//将封装后的管一次性发给复述
结束=System.currentTimeMillis ();
system . out。println(“管共插入:[" + redis.dbSize() + "]条. .”);
system . out。println(“2、使用管批量设值耗时”+(结束-开始)/1000 +“秒…”);//- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -//hmget
<字符串>键集=redis.keys (“key_ *”);//将上面设值所有结果键查询出来//直接使用能hgetall
开始=System.currentTimeMillis ();
Map =新HashMap <字符串,Map ();
(字符串关键:键){//此处键根据以上的设值结果,共10000个有循环10000次
结果。把(关键redis.hgetAll(键));//使用复述对象根据键值去取的值,将结果放入结果对象
}
结束=System.currentTimeMillis ();
system . out。println(“共取值:[" + redis.dbSize() + "]条. .”);
system . out。println(“3,未使用管批量取值耗时”+(结束-开始)/1000 +“秒…”);//使hgetall用管道
result.clear ();
开始=System.currentTimeMillis ();
(字符串关键:键){
pipe.hgetAll(关键);//使用管封装需要取值的键,此时还停留在客户端,并未真正执行查询请求
}
pipe.sync ();//提交到复述,进行查询
结束=System.currentTimeMillis ();
system . out。println(“管共取值:[" + redis.dbSize() + "]条. .”);
system . out。println(“4、使用管批量取值耗时”+(结束-开始)/1000 +“秒…”);
redis.disconnect ();
} 
三,原生批命令(mset mget)与管道对比
1,原生批命令是原子性,管道是非原子性
(原子性概念:一个事务是一个不可分割的最小工作单位,要么都成功要么都失败。原子操作是指你的一个业务逻辑必须是不可拆分的。处理一件事情要么都成功,要么都失败,原子不可拆分)
2,原生批命令一命令多个键,但管道支持多命令(存在事务),非原子性
3,原生批命令是服务端实现,而管道需要服务端与客户端共同完成





