
下文主要给大家带来深入掌握MySQL的知识,希望这些内容能够带给大家实际用处,这也是我编辑深入掌握MySQL的知识这篇文章的主要目的。好了,废话不多说,大家直接看下文吧。
数据库基本原理
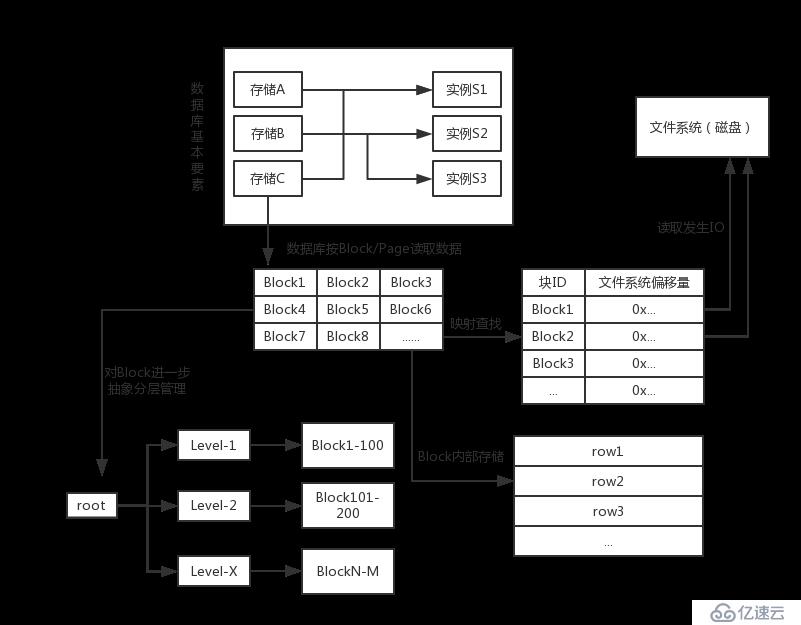
第一,数据库的组成:存储+实例
不必多说,数据当然需要存储;存储了还不够,显然需要提供程序对存储的操作进行封装,对外提供增删改查的API,即实例。
一个存储,可以对应多个实例,这将提高这个存储的负载能力以及高可用;多个存储可以分布在不同的机房,地域,将实现容灾。
第二,按块或页面读取数据
用大腿想也知道,数据库不可能按行读取数据(为什么?,^_^)。实质上,数据库,如Oracle/MySQL,都是基于固定大小(比如16K)的物理块(Block or Page,我这里就不区分统一称为Block)来实现调度和管理的。要知道Block是数据库的概念,如何对应到文件系统呢?显然需要指出“这个Block的地址在哪里”,当查找到地址后,读取固定大小的数据就相当于完成了Block的读取了。
数据库很聪明的,它不会仅仅只读取需要读取的Block,它还会替我们把附近的Block块都读取加载至内存。实际上,这是为了减少IO次数,提高命中率。事实上,一个Block块的附近Block也是热点数据,这种处理方式很有必要!
第三,磁盘IO是数据库的性能瓶颈
毫无疑问,数据在磁盘上,少不了磁盘IO。什么磁头旋转,定位磁道,寻址的过程,就不说了,我们是程序员,也管不了这些。但是这个过程确实是非常耗时的,和内存读取不是一个数量级,所以后来出现了很多方式来减少IO,提升数据库性能。
Hello,B+Tree
在MySQL中,不同存储引擎对索引的实现方式是不同的,这里将重点分析MyISAM和Innodb。
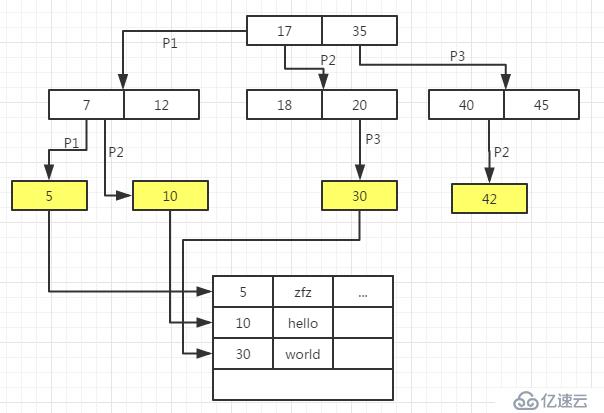
我们知道对于MyISAM引擎而言,数据文件和索引文件是分离的。从图中也可以看出,通过索引查找到后,就得到了数据的物理地址,然后根据地址定位数据文件中的记录即可。这种方式也叫"非聚集索引"。
而对于Innodb引擎而言,数据文件本身是索引文件!通俗点说,叶子节点上,MyISAM存储的是记录的物理地址,而Innodb上存储的是数据内容,这种方式即"聚集索引"。
另外一点需要注意的是,对于Innodb而言,主键索引中叶子节点存储的是数据内容,而普通索引的叶子节点中存储的是主键值!也就是说,对于Innodb的普通索引字段查找,先通过普通索引的B+Tree查找到主键后,然后通过主键索引的B+Tree进行查找。从这里你可以看出,对于Innodb而言,主键的建立非常重要!
而对于MyISAM而言,主键索引和普通索引仅仅的区别在于主键只需要查找到一条记录即可停止,而普通索引允许重复,找到一条记录后需要继续查找,在结构上没有区别,如上图所示。
深入B+Tree
提几个问题:
为什么B+Tree把真实的数据放到叶子节点,而不是内层节点?
为什么我们说索引字段要尽可能短,最好是单调递增的?
为什么复合索引存在最左匹配原则?
范围查询(>,<,between,like)对最左匹配有什么影响?
关于B+Tree的一些数学理论,咱们就不玩了,至少一点可以肯定的是:数据表的数据量N=F(树的高度h,每个Block存储的索引的个数m)。在N一定的情况下,索引字段越小,那么m会越大,这意味着h将越小!树越低,当然查找的更快!
如果内层节点存放真实的数据,显然m会变小,树将变高。
在实际应用中,我们应该尽可能采用单调递增的字段作为主键,一方面不会使得索引的数据结构变大,减小了索引占用的空间;另一方面也不会频繁的分裂B+Tree,使得效率下降。
比如复合索引(name,age,sex),B+Tree会优先比较name来确定下一步的搜索方向。如果突然来了个(age,sex),根本上就无从下手。这也是符合常理的,对于一本书,我们说“找到第几章第几节的XXX”,从没有听说过“找到第几节的XXX”!这是复合索引的重要特性,即最左匹配特性。
假设存在复合索引(name,age,sex),我们在进行select的时候,并没有按照这个顺序进行,而是sex='man' 和name=& # 39; zfz& # 39;是和年龄=27日否会使用索引呢?数据库是很聪明的,在SQL优化的时候,会自动帮助我们调整!但是如果缺失了复合索引的第一列,数据库也将无能为力呢。




