
Fluentd是一个日志收集系统,它的特点在于其各部分均是可定制化的,你可以通过简单的配置,将日志收集到不同的地方。
目前开源社区已经贡献了下面一些存储插件:MongoDB,,复述,,,CouchDB, Amazon S3,, Amazon SQS,,,, 0 mq, AMQP,,推迟,,咆哮等等。
本文要介绍的是在的最新版中已经内置的支持。主要通过一个收集Apache日志的例子来说明其使用方法:
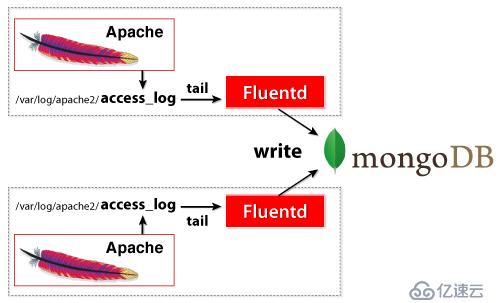
机制图解
翻译: http://blog.nosqlfan.com/html/3521.html
机制图解
安装
为了完成相关的测试,需要安装下面一些组件: 李- <>与MongoDB Fluentd插件李 <李> MongoDB李 <李> Apache(组合日志格式)
gem安装fluent-plugin-mongo来进行安装
- <李> Debian软件包李 <李> RPM包 <李> MongoDB下载
配置
如果你是使用上面的deb/rpm包安装的Fluentd,那么配置文件位置在: 首先我们编辑配置文件中的源来设置日志来源& lt; source> 类型的尾巴 格式apache 路径/var/log/apache2/access_log 标签mongo.apache & lt;/source>其中: 李
- <> <>强类型尾巴:尾方式是Fluentd内置的输入方式,其原理是不停地从源文件中获取新的日志。 <李> <强>格式apache :指定使用Fluentd内置的apache日志解析器。 <李> <>强路径/var/log/apache2/access_log :指定日志文件位置。 <李> <强>标记mongo。李apache :
& lt;匹配mongo。* *比; #插件类型 蒙戈类型 # mongodb数据库+收藏 数据库apache 收集访问 # mongodb主机+端口 主机主机 端口27017 #间隔 flush_interval 10年代 & lt;/match>匹配标签后面可以跟正则表达式以匹配我们指定的标签,只有匹配成功的标签对应的日志才会运用里面的配置。配置中的其它项都比较好理解,看注释就可以了,其中flush_interval是用来控制多长时间将日志写入MongoDB一次。
测试
用ab工具对Apache进行访问,以产生相应的访问日志以供收集100 ab - n - c 10 http://localhost/然后我们在MongoDB中就能看到收集到的日志了 <>以前mongo美元 比;使用apache 比;db.access.find () {" _id ": ObjectId (" 4 ed1ed3a340765ce73000001 "),“主机”:“127.0.0.1”,“用户”:“-”,“方法”:“得到”、“路径”:“/薄ⅰ按搿?“200”,“大小”:“44”,“时间”:ISODate (2011 - 11 - 27 t07:56:27z)} {" _id ": ObjectId (" 4 ed1ed3a340765ce73000002 "),“主机”:“127.0.0.1”,“用户”:“-”,“方法”:“得到”、“路径”:“/薄ⅰ按搿?“200”,“大小”:“44”,“时间”:ISODate (2011 - 11 - 27 t07:56:34z)} {" _id ": ObjectId (" 4 ed1ed3a340765ce73000003 "),“主机”:“127.0.0.1”,“用户”:“-”,“方法”:“得到”、“路径”:“/薄ⅰ按搿?“200”,“大小”:“44”,“时间”:ISODate (2011 - 11 - 27 t07:56:34z)} blog.treasure-data.com
翻译: http://blog.nosqlfan.com/html/3521.html




