
今天就跟大家聊聊有关Python3中实现数据标准化的方法有哪些,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
一、[0,1]标准化
[0, 1]标准化是最基本的一种数据标准化方法,指的是将数据压缩到0 ~ 1之间。
标准化公式如下
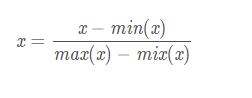
代码实现
或者
二、z分数标准化
z分数标准化是基于数据均值和方差的标准化化方法。标准化后的数据是均值为0,方差为1的正态分布。这种方法要求原始数据的分布可以近似为高斯分布,否则效果会很差。
标准化公式如下
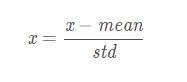
下面,我们看看为什么经过这种标准化方法处理后的数据为是均值为0,方差为1
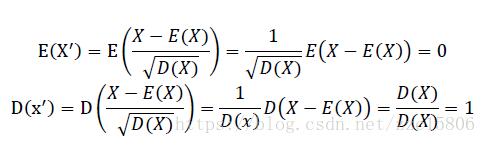
代码实现
或者
补充:Python数据预处理:彻底理解标准化和归一化
数据预处理
数据中不同特征的量纲可能不一致,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果,因此,需要对数据按照一定比例进行缩放,使之落在一个特定的区域,便于进行综合分析。
常用的方法有两种:
最大 - 最小规范化:对原始数据进行线性变换,将数据映射到[0,1]区间
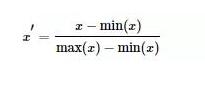
Z-Score标准化:将原始数据映射到均值为0、标准差为1的分布上
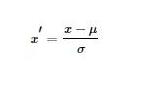
为什么要标准化/归一化?
提升模型精度:标准化/归一化后,不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
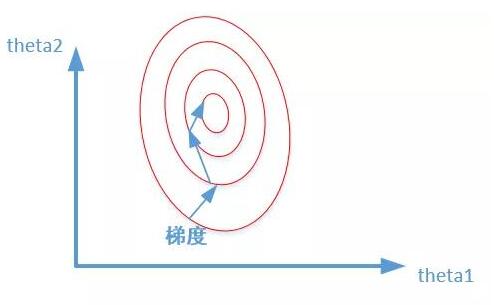
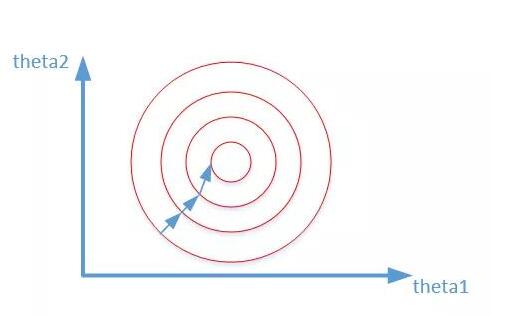
加速模型收敛:标准化/归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
如下图所示:
哪些机器学习算法需要标准化和归一化
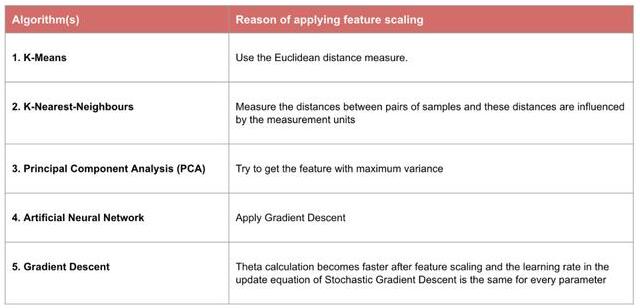
1)需要使用梯度下降和计算距离的模型要做归一化,因为不做归一化会使收敛的路径程z字型下降,导致收敛路径太慢,而且不容易找到最优解,归一化之后加快了梯度下降求最优解的速度,并有可能提高精度。比如说线性回归、逻辑回归、adaboost、xgboost、GBDT、SVM、NeuralNetwork等。需要计算距离的模型需要做归一化,比如说KNN、KMeans等。
2)概率模型、树形结构模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、随机森林。
彻底理解标准化和归一化
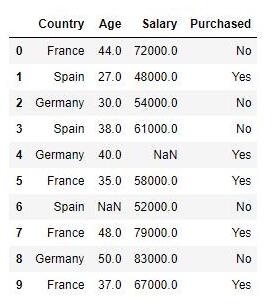
示例数据集包含一个自变量(已购买)和三个因变量(国家,年龄和薪水),可以看出用薪水范围比年龄宽的多,如果直接将数据用于机器学习模型(比如KNN、KMeans),模型将完全有薪水主导。




