介绍 import pandas as pd
#,数据
data =, pd.DataFrame ({& # 39; column1 # 39;: [& # 39; key1& # 39; & # 39; key1& # 39;, & # 39; key2& # 39;, & # 39; key2& # 39;],
,,,& # 39;column2& # 39;: [& # 39; value1 # 39; & # 39; value2 # 39;, & # 39; value3 # 39;, & # 39; value3 # 39;]})
打印(数据),
# Grouped dict类型
时间=data_dict data.groupby (& # 39; column1 # 39;) .column2.apply(列表).to_dict (),
打印(data_dict) , column1 column2
0,key1 value1
1,key1 value2
2,key2 value3
3,,key2 value3
{& # 39;key1& # 39;:, (& # 39; value1 # 39;,, & # 39; value2 # 39;],, & # 39; key2& # 39;:, (& # 39; value3 # 39;,, & # 39; value3 # 39;]} import pandas as pd
#,数据
df =, pd.DataFrame ({& # 39; column1 # 39;: [& # 39; key1& # 39; & # 39; key1& # 39;, & # 39; key2& # 39;, & # 39; key2& # 39;],
,,,& # 39;column2& # 39;: [& # 39; value1 # 39; & # 39; value2 # 39;, & # 39; value1 # 39;, & # 39; value2 # 39;],
,,,& # 39;column3& # 39;: [& # 39; value11& # 39; & # 39; value11& # 39;, & # 39; value22& # 39;, & # 39; value22& # 39;],
,,,& # 39;column4& # 39;: [& # 39; value44& # 39; & # 39; value44& # 39;, & # 39; value55& # 39;, & # 39; value55& # 39;]}),
# Grouped dict类型
时间=data_dict df.groupby (& # 39; column1 # 39;)苹果(lambda x:,{坳:x (col) .tolist (), for col 拷贝x.columns if col !=, & # 39; column2& # 39;}) .to_dict ()
打印(data_dict),
时间=data_dict2 df.groupby (& # 39; column1 # 39;)苹果(lambda x:,{坳:x (col) .tolist () [0], if col !=, & # 39; column2& # 39;, else x (col) .tolist (), for col 拷贝x.columns}) .to_dict ()
打印(data_dict2) # data_dict
{
& # 39;才能key1& # 39;:, {
,,,& # 39;column1 # 39;:, (& # 39; key1& # 39;,, & # 39; key1& # 39;),,
,,,& # 39;column3& # 39;:, (& # 39; value11& # 39;,, & # 39; value11& # 39;),,
,,,& # 39;column4& # 39;:, (& # 39; value44& # 39;,, & # 39; value44& # 39;】
,,},
& # 39;才能key2& # 39;:, {
,,,& # 39;column1 # 39;:, (& # 39; key2& # 39;,, & # 39; key2& # 39;),,
,,,& # 39;column3& # 39;:, (& # 39; value22& # 39;,, & # 39; value22& # 39;),,
,,,& # 39;column4& # 39;:, (& # 39; value55& # 39;,, & # 39; value55& # 39;】
,,}
}
# data_dict2
{
& # 39;才能key1& # 39;:, {
,,,& # 39;column1 # 39;:, & # 39; key1& # 39;,,
,,,& # 39;column2& # 39;:, (& # 39; value1 # 39;,, & # 39; value2,),,
,,,& # 39;column3& # 39;:, & # 39; value11& # 39;,,
,,,& # 39;column4& # 39;:, & # 39; value44& # 39;
,,},
& # 39;才能key2& # 39;:, {
,,,& # 39;column1 # 39;:, & # 39; key2& # 39;,,
,,,& # 39;column2& # 39;:, (& # 39; value1 # 39;,, & # 39; value2,),,
,,,& # 39;column3& # 39;:, & # 39; value22& # 39;,,
,,,& # 39;column4& # 39;:, & # 39; value55& # 39;
,,}
}
这篇文章将为大家详细讲解有关熊猫怎么实现某一列分组以及其他列合并成列表,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
熊猫列转换为字典,但将相同第一列(键)的所有值合并为一个键
形式一:
输出结果:
形式二:
输出结果:
<>强补充:大熊猫中,利用groupby分组后,对字符串字段进行合并拼接
在熊猫里对于数值字段而言,groupby后可以用sum (), max()等方法进行简单的处理,对于字符串字段,如果把它们的值拼接在一起,可以用使用str.cat()和λ方法。
如,将下面表格中的内容,对技能字段按照身份证进行分组合并
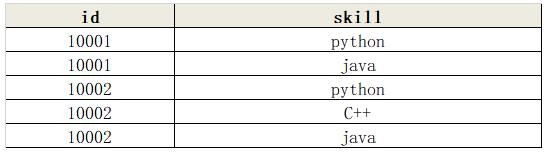 import pandas as pd
file_name=& # 39; test.xlsx& # 39;
df=pd.read_excel (file_name)
data=https://www.yisu.com/zixun/df.groupby (“id”)(“技能”)苹果(λx: x.str.cat(9月=':')).reset_index ()
打印(数据)
import pandas as pd
file_name=& # 39; test.xlsx& # 39;
df=pd.read_excel (file_name)
data=https://www.yisu.com/zixun/df.groupby (“id”)(“技能”)苹果(λx: x.str.cat(9月=':')).reset_index ()
打印(数据)
效果如下: