最近在给HBase集群进行扩容,然而事事不顺:
1。新添加的机器中有一台竟然无故重启,这个问题直接推给了系统部。
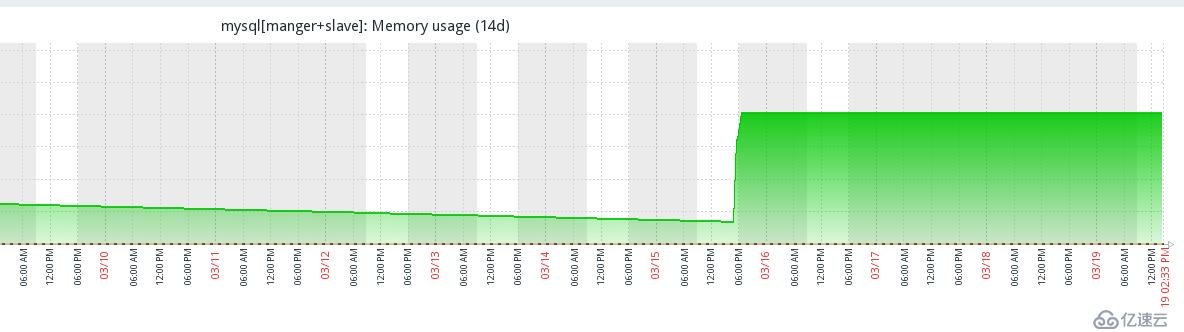
2。部署完HDFS和HBase后,启动都没有任何问题,然而过一夜后,HBase节点全部宕掉。
更奇怪的是,以前老集群中的节点没有问题,运行正常,只有新添加的几个节点宕掉,而且HDFS运行也正常(除了机器重启的那个节点)。
于是各种查看日志。
HBase日志显示如下:JVM暂停时间过长,导致无法与饲养员通信,被动物园管理员认为该节点已经宕掉,于是就关闭了该节点。
是不是真的发生了完整GC吗?为什么会发生GC,暂停应用呢?老集群中的机器为什么没问题呢?由于对GC理解太浅,于是产生了各种问题,网上也没查到具体答案,只能一点一点查询,理解,梳理。
2015 - 10 - 13,23:47:12,295 WARN , [JvmPauseMonitor], util.JvmPauseMonitor:, Detected pause 拷贝JVM 或是host machine (eg GC):, pause of approximately 83095 ms
GC pool “ParNew”, had 集合(s):,数=2,=216毫秒的时间
GC pool “ConcurrentMarkSweep”, had 集合(s):,数=2,=330毫秒的时间
2015 - 10 - 13,23:47:12,295 WARN , [regionserver60020], util.Sleeper:, slept 我方表示歉意85995小姐instead of 3000 ms,,却;能够is likely due 用a long garbage collecting pause 以及它's usually 坏,阅读http://hbase.apache.org/book.html trouble.rs.runtime.zkexpired
2015 - 10 - 13,23:47:12,295 INFO , [regionserver60020-SendThread (zookeeper2:2181)], zookeeper.ClientCnxn:, Client session timed ,, have not heard 得到server 拷贝95659小姐for sessionid 0 x25053f6801406ac, closing socket connection 以及attempting 重新连接
2015 - 10 - 13,23:47:12,291 WARN , [regionserver60020.compactionChecker], util.Sleeper:, slept 我方表示歉意89894小姐instead of 10000,女士,却;能够is likely due 用a long garbage collecting pause 以及它's usually 坏,阅读http://hbase.apache.org/book.html trouble.rs.runtime.zkexpired
2015 - 10 - 13,23:47:12,291 WARN , [regionserver60020.periodicFlusher], util.Sleeper:, slept 我方表示歉意89894小姐instead of 10000,女士,却;能够is likely due 用a long garbage collecting pause 以及它's usually 坏,阅读http://hbase.apache.org/book.html trouble.rs.runtime.zkexpired
2015 - 10 - 13,23:47:12,291 INFO , [regionserver60020-SendThread (zookeeper3:2181)], zookeeper.ClientCnxn:, Client session timed ,, have not heard 得到server 拷贝89644小姐for sessionid 0 x1505ebc2da3010f, closing socket connection 以及attempting 重新连接
2015 - 10 - 13,23:47:12,397 FATAL [regionserver60020], regionserver.HRegionServer:, ABORTING region server hregion151, 1444732375821: 60020年,org.apache.hadoop.hbase.YouAreDeadException:, server REPORT 拒绝;,currently processing hregion151, 60020, 1444732375821, as dead 服务器
在HBase的安装目录下有个gclog。0文件,记录了HBase运行时发生的垃圾回收信息。
但是各种查看后,也没发现什么问题。(或许是对GC不懂的缘故吧,不懂就查,学呗)。
2015 - 10 - 13 - t18:35:47.314 + 0800:, 165.893:, (GC [1, CMS-initial-mark:, 32523 k (63872 k)], 35370 k (83008 k),,, 0.0185230秒],[*:用户=0.01,sys=0.02,,真正的=0.01,秒),
2015 - 10 - 13 - t18:35:47.333 + 0800:, 165.912:, (CMS-concurrent-mark-start)
2015 - 10 - 13 - t18:35:47.402 + 0800:, 165.981:, [CMS-concurrent-mark: 0.046/0.069,秒],[*:用户=0.32,sys=0.03,,真正的=0.07,秒),
2015 - 10 - 13 - t18:35:47.402 + 0800:, 165.982:, (CMS-concurrent-preclean-start)
2015 - 10 - 13 - t18:35:47.411 + 0800:, 165.990:, [CMS-concurrent-preclean: 0.008/0.009,秒],[*:用户=0.02,sys=0.00,,真正的=0.01,秒),
2015 - 10 - 13 - t18:35:47.411 + 0800:, 165.990:, (CMS-concurrent-abortable-preclean-start)
2015 - 10 - 13 - t18:35:47.414 + 0800:, 165.993:, (165.993: GC [ParNew:, 18503 k, 2112 k (19136 k),,, 0.0681050秒),51027 k, 37708 k (83008 k),,, 0.0682600秒],[*:用户=0.03,sys=0.07,,真正的=0.06,秒),
2015 - 10 - 13 - t18:35:47.535 + 0800:, 166.115:, [CMS-concurrent-abortable-preclean: 0.028/0.124,秒],[*:用户=0.15,sys=0.09,,真正的=0.13,秒),
2015 - 10 - 13 - t18:35:47.536 + 0800:, 166.115:, (GC [YG 入住率:,14168,K (19136, K)) 166.115:, (Rescan (平行),,,,0.0024340秒)166.117:,(weak refs 处理,,,0.0001320秒],[1,CMS-remark:, 35596 K (63872 K)], 49765 K (83008 K),,, 0.0026970秒],[*:用户=0.03,sys=0.00,,真正的=0.00,秒),
null
null
null
null
null
null
null
null
null
null
null
null