本篇文章为大家展示了怎么在Python中使用支持向量机SVM,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
<强>一、导入sklearn算法包
Scikit-Learn库已经实现了所有基本机器学习的算法,具体使用详见官方文档说明:http://scikit-learn.org/stable/auto_examples/index.html。
skleran中集成了许多算法,其导入包的方式如下所示,
逻辑回归:sklearn。linear_model进口LogisticRegression
朴素贝叶斯:从sklearn。naive_bayes进口GaussianNB
K -近邻:sklearn。邻居进口KNeighborsClassifier
决策树:从sklearn。树导入DecisionTreeClassifier
支持向量机:从sklearn进口svm
<强>二,sklearn中svc的使用
(1)使用numpy中的loadtxt读入数据文件
loadtxt()的使用方法:

帧:文件路径.eg: C:/数据/iris.txt。
dtype:数据类型.eg:浮动,str等。
分隔符:分隔符.eg:“& # 39;。
转换器:将数据列与转换函数进行映射的字典.eg:{} 1:有趣,含义是将第2列对应转换函数进行转换。
usecols:选取数据的列。
<强>以虹膜兰花数据集为例子:
由于从UCI数据库中下载的虹膜原始数据集的样子是这样的,前四列为特征列,第五列为类别列,分别有三种类别Iris-setosa, Iris-versicolor, Iris-virginica。
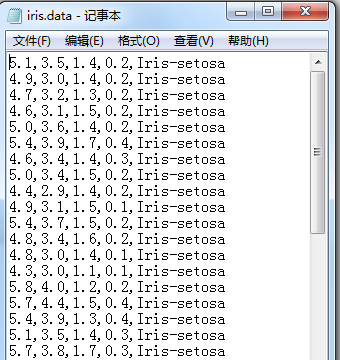
当使用numpy中的loadtxt函数导入该数据集时,假设数据类型dtype为浮点型,但是很明显第五列的数据类型并不是浮点型。
因此我们要额外做一个工作,即通过loadtxt()函数中的转换器参数将第五列通过转换函数映射成浮点类型的数据。
首先,我们要写出一个转换函数:
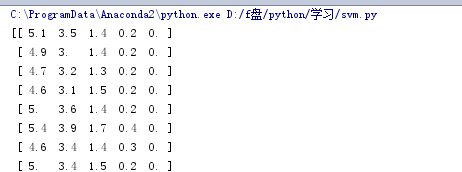
接下来读入数据,转换器={4:iris_type}中“4”指的是第5列:
读入结果:
(2)将虹膜分为训练集与测试集
1。split(数据,分割位置,轴=1(水平分割)或0(垂直分割)).
2。x=x(:,: 2)是为方便后期画图更直观,故只取了前两列特征值向量训练。
3。sklearn.model_selection。train_test_split随机划分训练集与测试集.train_test_split (train_data、train_target test_size=数字,random_state=0)
参数解释:
train_data:所要划分的样本特征集
<李>train_target:所要划分的样本结果
<李>test_size:样本占比,如果是整数的话就是样本的数量
<李>random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编的号,在需要重复试验的时候,保证得到一组一样的随机数比。如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但0填或不填,每次都会不一样。随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
(3)训练svm分类器
内核=& # 39;线性# 39;时,为线性核,C越大分类效果越好,但有可能会过拟合(defaul C=1)。
内核=& # 39;rbf # 39;时(默认),为高斯核,伽马值越小,分类界面越连续;伽马值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
decision_function_shape=& # 39;表达# 39;时,为一个v,即一个类别与其他类别进行划分,
decision_function_shape=& # 39;蛋# 39;时,为一个v> print clf.score (x_train, y_train), #,精度 时间=y_hat clf.predict (x_train) show_accuracy (y_hat, y_train, & # 39;训练集& # 39;) print clf.score (x_test, y_test) 时间=y_hat clf.predict (x_test) show_accuracy (y_hat, y_test, & # 39;测试集& # 39;)