介绍 def f (x1, x2):
y 才能;0.5=,,*,np.sin (x1), +, 0.5, *, np.cos (x2), +, 0.1, *, x1 +, 3
return 才能;y
def load_data ():
时间=x1_train 才能;np.linspace (0, 50500)
时间=x2_train 才能;np.linspace (-10、10500)
data_train 才能=,np.array ([[x1, x2, f (x1, x2), +, (np.random.random (1) -0.5)], for x1, x2 拷贝zip (x1_train, x2_train)))
时间=x1_test 才能;np.linspace (0 50100) +, 0.5, *, np.random.random (100)
时间=x2_test 才能;np.linspace (-10、10100), +, 0.02, *, np.random.random (100)
data_test 才能=,np.array ([[x1, x2, f (x1, x2)], for x1, x2 拷贝zip (x1_test, x2_test)))
return 才能;data_train, data_test import numpy as np
import matplotlib.pyplot as plt
# # # # # # # # # # # 1。数据生成部分# # # # # # # # # #
def f (x1, x2):
y 才能;0.5=,,*,np.sin (x1), +, 0.5, *, np.cos (x2), +, 3, +, 0.1, *, x1
return 才能;y
def load_data ():
时间=x1_train 才能;np.linspace (0, 50500)
时间=x2_train 才能;np.linspace (-10、10500)
data_train 才能=,np.array ([[x1, x2, f (x1, x2), +, (np.random.random (1) -0.5)], for x1, x2 拷贝zip (x1_train, x2_train)))
时间=x1_test 才能;np.linspace (0 50100) +, 0.5, *, np.random.random (100)
时间=x2_test 才能;np.linspace (-10、10100), +, 0.02, *, np.random.random (100)
data_test 才能=,np.array ([[x1, x2, f (x1, x2)], for x1, x2 拷贝zip (x1_test, x2_test)))
return 才能;data_train data_test
火车,,test 为,load_data ()
x_train, y_train =,火车(:,:2),火车(:2),#数据前两列是x1, x2 第三列是y,这里的y有随机噪声
x_test y_test =,测试(:,:2),测试(:2),#,同上,不过这里的y没有噪声
# # # # # # # # # # # 2。回归部分# # # # # # # # # #
def try_different_method(模型):
model.fit才能(x_train y_train)
时间=score 才能;model.score (x_test, y_test)
时间=result 才能;model.predict (x_test)
plt.figure才能()
plt.plot才能(np.arange (len(结果)),y_test, & # 39; & # 39;,标签=& # 39;true 价值# 39;)
plt.plot才能(np.arange (len(结果)),因此,& # 39;ro & # 39;,标签=& # 39;predict 价值# 39;)
plt.title才能(& # 39;分数:,% f # 39; %得分)
plt.legend才能()
plt.show才能()
# # # # # # # # # # # 3。具体方法选择# # # # # # # # # #
# # # # 3.1决策树回归# # # #
得到sklearn import 树
时间=model_DecisionTreeRegressor tree.DecisionTreeRegressor ()
# # # # 3.2线性回归# # # #
得到sklearn import linear_model
时间=model_LinearRegression linear_model.LinearRegression ()
# # # # 3.3支持向量机回归# # # #
得到sklearn import 支持向量机
时间=model_SVR svm.SVR ()
# # # # 3.4资讯回归# # # #
得到sklearn import 邻居
时间=model_KNeighborsRegressor neighbors.KNeighborsRegressor ()
# # # # 3.5随机森林回归# # # #
得到sklearn import 合奏
时间=model_RandomForestRegressor ensemble.RandomForestRegressor (n_estimators=20) #这里使用20个决策树
# # # # 3.6演回归# # # #
得到sklearn import 合奏
时间=model_AdaBoostRegressor ensemble.AdaBoostRegressor (n_estimators=50) #这里使用50个决策树
# # # # 3.7 gbrt回归# # # #
得到sklearn import 合奏
时间=model_GradientBoostingRegressor ensemble.GradientBoostingRegressor (n_estimators=100) #这里使用100个决策树
# # # # 3.8装袋回归# # # #
得到sklearn.ensemble import BaggingRegressor
时间=model_BaggingRegressor BaggingRegressor ()
# # # # 3.9 extratree极端随机树回归# # # #
得到sklearn.tree import ExtraTreeRegressor
时间=model_ExtraTreeRegressor ExtraTreeRegressor ()
# # # # # # # # # # # 4。具体方法调用部分# # # # # # # # # #
try_different_method (model_DecisionTreeRegressor)
这篇文章将为大家详细讲解有关怎么在Python中利用sklearn实现一个回归算法,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
使用sklearn做各种回归
基本回归:线性,决策树,支持向量机,然而
集成方法:随机森林,演算法,GradientBoosting,装袋,ExtraTrees
<强> 1。数据准备
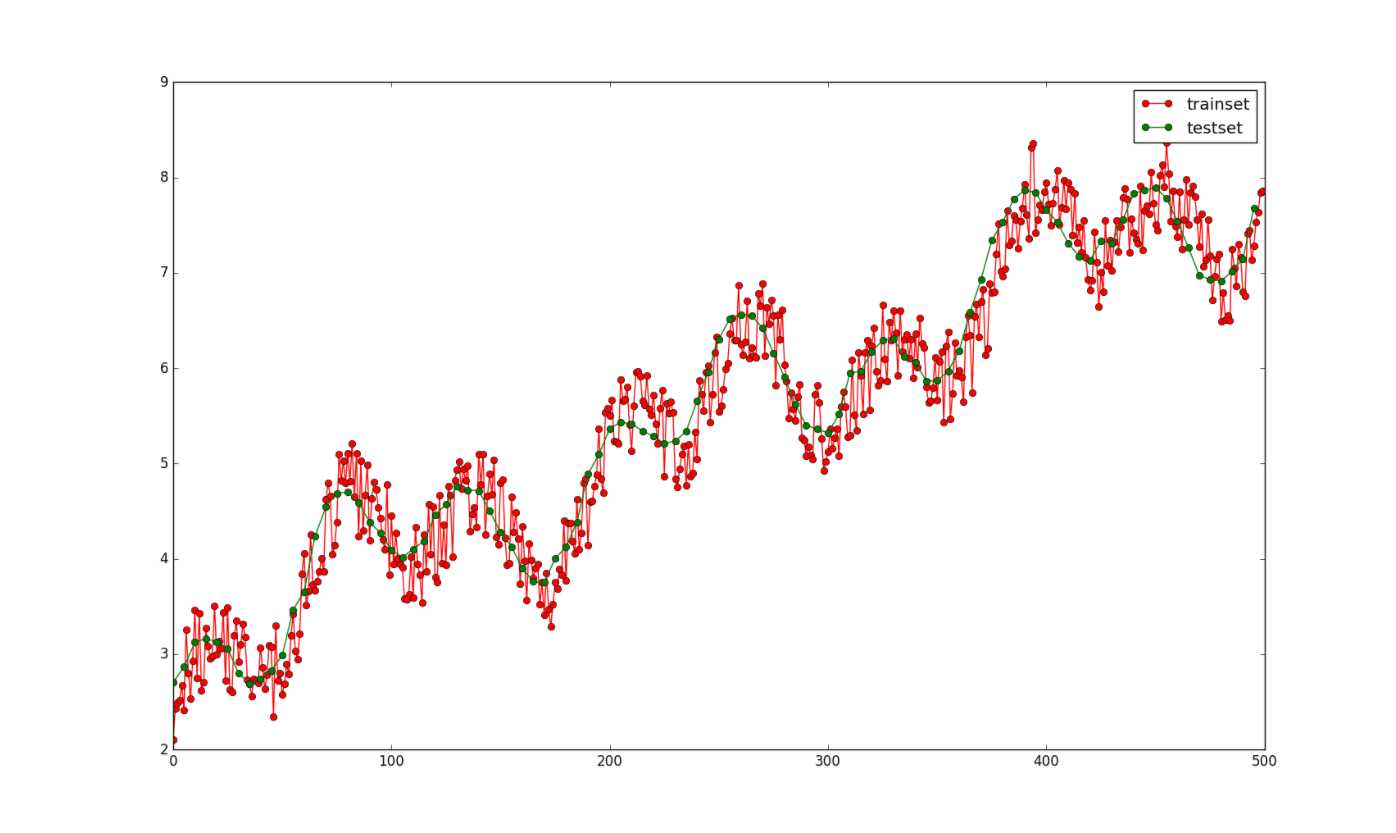
为了实验用,我自己写了一个二元函数,y=0.5 * np.sin (x1) + 0.5 * np.cos (x2) + 0.1 * x1 + 3。其中x1的取值范围是0 ~ 50,x2的取值范围是-10 ~ 10,x1和x2的训练集一共有500个,测试集有100个,其中,在训练集的上加了一个-0.5 ~ 0.5的噪声。生成函数的代码如下:
其中训练集(y上加有-0.5 ~ 0.5的随机噪声)和测试集(没有噪声)的图像如下:
<强> 2。scikit-learn的简单使用
scikit-learn非常简单,只需实例化一个算法对象,然后调用符合()函数就可以了,适合之后,就可以使用<代码>预测()函数来预测了,然后可以使用<代码>得分()函数来评估预测值和真实值的差异,函数返回一个得分。
完整程式化代码为: