聚合(聚合)为集合文档数据提供各种处理数据方法,并返回计算结果.MongoDB提供了3种方式来执行聚合命令:聚合管道方法,使用映射-规约模式方法和单一目标聚合方法。
1。聚合管道方法
聚合管道方法又可以直接理解为合计流水线法,就是把集合里若干含数值型的文档记录,其键对应的值进行各种分类统计。该方法支持分片集合操作。
语法:db.collection_name.aggregate (
,,,,({$匹配:{& lt;字段>}},//统计查找条件
,,,,,,,,{$组:{& lt; fieldl祝辞,& lt;field2祝辞}}
,,,,,,,,//fieldl为分类字段;field2为含各种统计操作符的数值型字段,如美元,avg美元,美元,美元马克斯,推动美元,美元addToSet,第一,去年美元操作符
_id:“goodsid"美元;,goodsid为分类字段名,_id为必须指定唯一性字段,不能改为其他名称的字段;总为统计结果字段名,可以是任意的符合起名规则的新名称。美元金额为求和操作符号,金额为美元求和字段,必须加上双引号。
2。使用映射-规约模式方法
语法:db.collection_name。mapreduce (
,,,,,,,,,,,,,,,,()函数{排放(& lt; this.field1> & lt; this.field2>)},
,,,,,,,,,,,,,,,函数(关键字,值){返回array.sum(值)},
,,,,,,,,,,,,,,,,{查询:{& lt; field>},: & lt;“resultname"祝辞}
命令说明:
,,,,()函数{排放(& lt; this.field1> & lt; this.field2>)},把集合对应的字段
,,,,把自field1值和求得值连同:<皉esultname"在一起返回。
,,,,查询:{& lt; field>}在集合里查询符合& lt; field>条件的文档。
,,,,该方式进行聚合运算,效率较聚合管道方式要低,而且使用更复杂。
3。单一目标聚合方法
该方法下,目前有两种聚合操作功能:db.collection_name.count()和db.collection_name.distinct ()。
(1)语法:db.collection_name。计数(查询、期权)
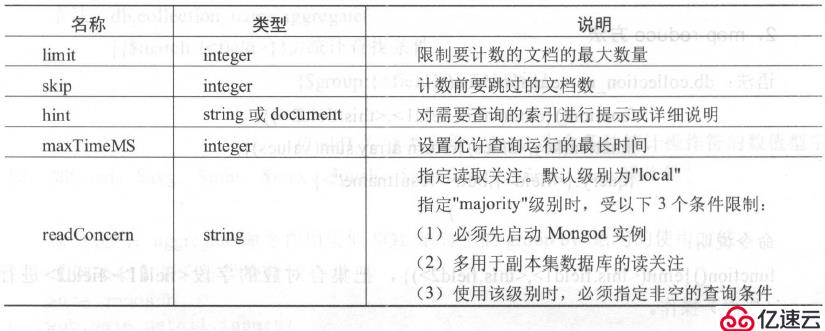
命令说明:统计集合里符合查询条件的文档数量,查询为查询条件,选择参数详细说明如表
统计符合条件的记录数
db.Sale_detail。计数({ok:假})
从第二条开始统计符合条件的记录数
db.Sale_detail。计数({好:假},{跳过:1})
统计指定键的不同值并返回不同值
db.Sale_detail.distinct (“goodsid")
单一目标聚合方法,可以直接在发现()后加点使用。
如goodsdb.Sale_detail.find ({ok:假}).count ()
goodsdb.Sale_detail.find ({ok:假}).count () .skip (1)