介绍
这期内容当中小编将会给大家带来有关怎么在Django中利用干草堆和嗖实现一个搜索功能,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
<强>安装和配置
安装所需包
pip install django-haystack
pip install 嗖
pip install jieba 去设置文件注册干草堆应用
INSTALLED_APPS =, (
,& # 39;干草堆# 39;,,#,注册全文检索框架
) 在设置文件中配置全文检索框架
#,全文检索框架的配置
HAYSTACK_CONNECTIONS =, {
,& # 39;默认# 39;:,{
#,才能使用呼引擎
& # 39;才能引擎# 39;:,& # 39;haystack.backends.whoosh_backend.WhooshEngine& # 39;
#,才能索引文件路径
& # 39;才能path & # 39;:, os.path.join (BASE_DIR, & # 39; whoosh_index& # 39;),
,}
}
#,当添加,修改,删除数据时,自动生成索引=HAYSTACK_SIGNAL_PROCESSOR & # 39; haystack.signals.RealtimeSignalProcessor& # 39; <>强索引文件的生成
要生成索引文件,首先你要配置,对哪些内容进行索引,比如商品名称,简介和详情;为了配置对数据库指定内容进行索引,我们要做如下步骤:
配置search_indexes。py文件
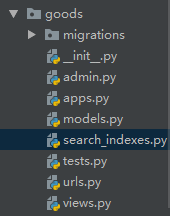
因为在django中数据库一般都是通过ORM生成的,首先我们在要在数据表对应的应用中创建一个search_indexes。py文件,例如,我现在要检索商品对应的表就是GoodsSKU表,而表是在货物应用下的,所以我在货物应用下新建search_indexes。py文件,截图如下:
在search_indexes。py文件中加入以下内容
#,定义索引类
得到haystack import 索引
#,导入你的模型类
得到goods.models import GoodsSKU
#,指定对于某个类的某些数据建立索引
#,索引类名格式:模型类名+指数
class GoodsSKUIndex (indexes.SearchIndex, indexes.Indexable):
,#索引字段,use_template=True指定根据表中的哪些字段建立索引文件的说明放在一个文件中=,,text indexes.CharField(文档=True, use_template=True)
,def get_model(自我):
#,才能返回你的模型类
return GoodsSKU才能
,#建立索引的数据
,def index_queryset(自我,,使用=None):
.objects.all return 才能self.get_model () () 指定要检索的内容
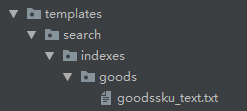
在模板文件夹下面新建搜索文件夹,在搜索文件夹下面新建索引文件夹,在索引文件夹下面新建要检索应用名的文件夹比如商品文件夹,在商品文件夹下面新建表名_text。txt,表名小写,所以目前的目录结构是这样的模板/搜索//商品/goodssku_text索引。txt,截图如下:
在goodssku_text。txt文件中指定你要根据表中的哪些字段建立索引数据,现在我们要根据商品的名称,简介,详情来建立索引,如下配置
#,指定根据表中的哪些字段建立索引数据
{{,object.name }}, #,根据商品的名称建立索引
{{,object.desc }}, #,根据商品的简介建立索引
{{,object.goods.detail }}, #,根据商品的详情建立索引 其中的对象可以理解为数据表对应的商品对象。
<强>生成索引文件
使用pycharm自带的命令行终端运行以下命令生成索引文件:
python管理。py rebuild_index
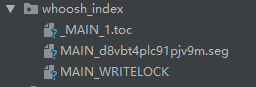
运行成功后,你可以在项目下看到类似如下索引文件
<强>使用全文检索
通过如上的配置,我们的数据索引已经建立了,现在我们要在项目中使用全文检索。
在需要使用检索的地方进行形式表单改造
& lt; form action=?search",方法=癵et"比;
,& lt; input 类型=皌ext",类=癷nput_text fl", name=皅",占位符=八阉魃唐贰氨?
,& lt; input 类型=皊ubmit",类=癷nput_btn fr", name=啊? value=https://www.yisu.com/zixun/八阉鳌?
如上所示,其中要注意的是:
发送方式必须使用得到,
搜索的输入框的名字必须是问;
配置检索对应的url