介绍
这期内容当中小编将会给大家带来有关怎么在Python项目中使用lxml库解析html文件,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
lxml是Python的一个html/xml解析并建立dom的库,lxml的特点是功能强大,性能也不错,xml包含了ElementTree, html5lib, beautfulsoup等库。
使用lxml前注意事项:先确保html经过了utf - 8解码,即<代码>代码=html.decode (& # 39; utf - 8 # 39; & # 39;忽略# 39;)>
具体用法:元素节点操作
1,,解析HTMl建立DOM
得到lxml import etree
时间=dom etree.HTML (html) 2,,查看dom中子元素的个数<代码> len (dom)
3,,查看某节点的内容:<代码> etree.tostring (dom[0])
4,,获取节点的标签名称:<代码> dom [0] .tag
5,,获取某节点的父节点:<代码> dom [0] .getparent()
6,,获取某节点的属性节点的内容:<代码> dom [0] . get(“属性名称“)
对xpath路径的支持:
xpath即为XML路径语言,是用一种类似目录树的方法来描述在XML文档中的路径比。如用“/崩醋魑舷虏慵都涞姆指簟5谝桓觥?氨硎疚牡档母诘?注意,不是指文档最外层节的标记点,而是指文档本身)。比如对于一个HTML文件来说,最外层的节点应该是“/html"。
xpath选取元素的方式:
1,,绝对路径,如<代码> page.xpath (“/html/身体/p")>
2,,相对路径,<代码> page.xpath (“//p")>

xpath筛选方式:
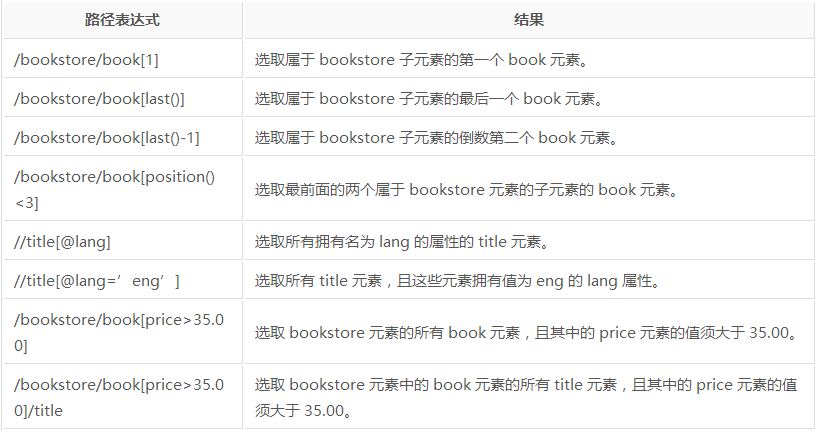
1,,选取元素时一个列表,可通过索引查找[n]
2,,通过属性值筛选元素<代码> p=page.xpath (“//p [@style=& # 39;字体大小:200% & # 39;]“)
3,,如果没有属性可以通过文本()(获取元素中文本)、位置()(获取元素位置),最后()等进行筛选
获取属性值
dom.xpath (.///@href) 获取文本
dom.xpath (“。///text ()“) 示例代码:
# !/usr/bin/Python
#,- *安康;编码:utf-8 - *
得到scrapy.spiders import 蜘蛛
得到lxml import etree
得到jredu.items import JreduItem
class JreduSpider(蜘蛛):
时间=name 才能;& # 39;tt # 39;, #爬虫的名字,必须的,唯一的
allowed_domains 才能=,(& # 39;sohu.com& # 39;】
start_urls 才能=,(
,,,& # 39;http://www.sohu.com& # 39;
,,)
def 才能解析(自我,,反应):
,,,content =, response.body.decode (& # 39; utf - 8 # 39;)
,,,dom =, etree.HTML(内容)
,,,for ul 拷贝dom.xpath (“//div [@class=& # 39; focus-news-box& # 39;]/div [@class=& # 39; list16& # 39;]/ul"):
,,,,,lis =, ul.xpath (“。/li")
,,,,,for li 拷贝lis):
,,,,,,,item =, JreduItem(), #定义对象
,,,,,,,if ul.index(李),==,0:
,,,,,,,,,strong =, li.xpath(“。//强/text ()“)
,,,,,,,,,li.xpath (“。//@href")
,,,,,,,,,项目[& # 39;标题# 39;]=,强大的[0]
,,,,,,,,,项目[& # 39;href # 39;],=, li.xpath (“。//@href") [0]
,,,,,,,其他的:
,,,,,,,,,la =, li.xpath(“。/[去年()]/text ()“)
,,,,,,,,,项目[& # 39;标题# 39;],[0]=,洛杉矶
,,,,,,,,,项目[& # 39;href # 39;],=, li.xpath(“。/[去年()]/href") [0]
,,,,,,,油品收率项目 上述就是小编为大家分享的怎么在Python项目中使用lxml库解析html文件了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注行业资讯频道。