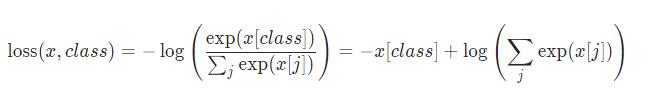这篇文章给大家介绍损失函数函数如何在Pytorch中使用,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
<强> 1。损失函数
损失函数,又叫目标函数,是编译一个神经网络模型必须的两个要素之一。另一个必不可少的要素是优化器。
损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离向量,绝对值向量等。
损失损失必须是标量,因为向量无法比较大小(向量本身需要通过范数等标量来比较)。
损失函数一般分为4种,平方损失函数,对数损失函数,HingeLoss 0 - 1损失函数,绝对值损失函数。
我们先定义两个二维数组,然后用不同的损失函数计算其损失值。
样本的值为:[[1],[1]]。
目标的值为:[[0,1],[2、3]]。
<强> 1神经网络。L1Loss
L1Loss计算方法很简单,取预测值和真实值的绝对误差的平均数即可。
最后结果是:1 .
它的计算逻辑是这样的:
先计算绝对差总和:| 0 - 1 | + | 1 | + | 2 | + | 3 |=4;
然后再平均:4/4=1。
<强> 2神经网络。SmoothL1Loss
SmoothL1Loss也叫作Huber损失,误差在(1,1)上是平方损失,其他情况是L1损失。
最后结果是:0.625 .
<强> 3神经网络。MSELoss
平方损失函数。其计算公式是预测值和真实值之间的平方和的平均数。
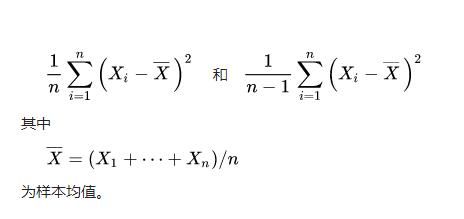 criterion =, nn.MSELoss ()
loss =,则(样本,,目标)
打印(损失)
criterion =, nn.MSELoss ()
loss =,则(样本,,目标)
打印(损失)
最后结果是:1.5 .
<强> 4神经网络。CrossEntropyLoss
交叉熵损失函数
花了点时间才能看懂它。
首先,先看几个例子,
需要注意的是,目标输入必须是张量长类型(int64位)
输出:
如果,改成pred=np.array([[0.8, 2.0, 2.0]]),输出,
后面两个输出一样。
先看它的公式,就明白怎么回事了:
 pred =, np.array ([[0.8,, 2.0, 2.0)))
时间=nClass pred.shape [1]
时间=target np.array ([0])
def labelEncoder (y):
tmp 才能=,np.zeros (shape =, (y.shape[0],,类))
for 才能小姐:拷贝范围(y.shape [0]):
,,,tmp[我][y[我]],=,1
return 才能,tmp
def crossEntropy (pred,目标):
时间=target 才能;labelEncoder(目标)
时间=pred 才能;softmax (pred)
时间=H 才能;-np.sum(目标* np.log (pred))
return 才能;H
时间=H crossEntropy (pred,目标)
pred =, np.array ([[0.8,, 2.0, 2.0)))
时间=nClass pred.shape [1]
时间=target np.array ([0])
def labelEncoder (y):
tmp 才能=,np.zeros (shape =, (y.shape[0],,类))
for 才能小姐:拷贝范围(y.shape [0]):
,,,tmp[我][y[我]],=,1
return 才能,tmp
def crossEntropy (pred,目标):
时间=target 才能;labelEncoder(目标)
时间=pred 才能;softmax (pred)
时间=H 才能;-np.sum(目标* np.log (pred))
return 才能;H
时间=H crossEntropy (pred,目标)
输出:
2.0334282107562287对上了!
再回头看看,公式