小编给大家分享一下如何配置python连接oracle读取excel数据写入数据库,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
一、配置python连接oracle并测试成功
网上有不少教程,但大部分都没那么详细,并且也没有说明连接单实例和连接集群的区别,这里先介绍连接oracle单实例的方式,后续再补充连接oracle集群方式。
版本:
window 10 64位
python 3.6.8
cx-Oracle 7.3.0
安装流程:
1、使用pip安装操作oracle的包:
pip install cx_Oracle==7.3.0
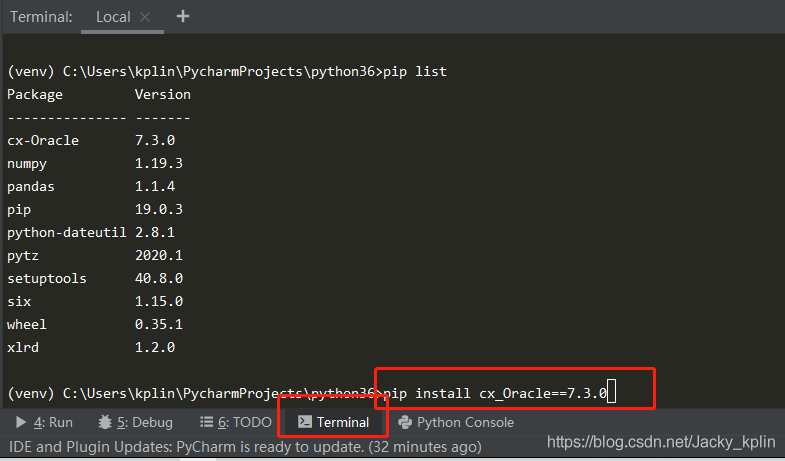
2、手动配置cx_Oracle临时客户端:
注意这里电脑是64位的,使用的即时客户端也是64位的,32位的需要另外到下面的下载地址找一下
2.1、解压下面的文件
链接: https://pan.baidu.com/s/12iMCBjKvl-Lao9iOHMT-yw
提取码: pxmq
oracle即时客户端使用说明:
https://docs.oracle.com/en/database/oracle/oracle-database/19/lnoci/instant-client.html#GUID-6895DB45-97AA-4738-9959-BD677D610186
oracle即时客户端下载地址:
https://www.oracle.com/database/technologies/instant-client/downloads.html
2.2、放置到D盘某个位置,例如:
2.3、配置环境变量
控制面板——系统和安全——系统
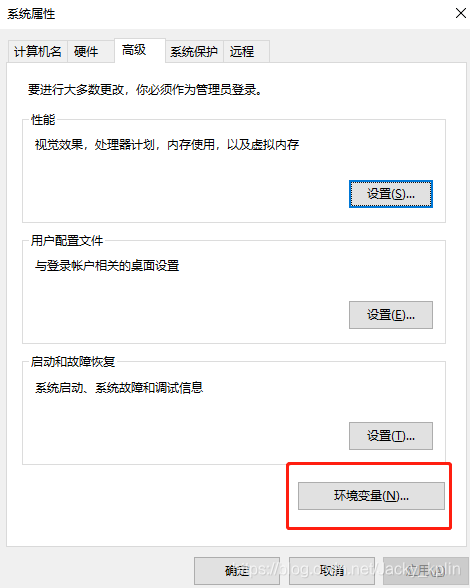
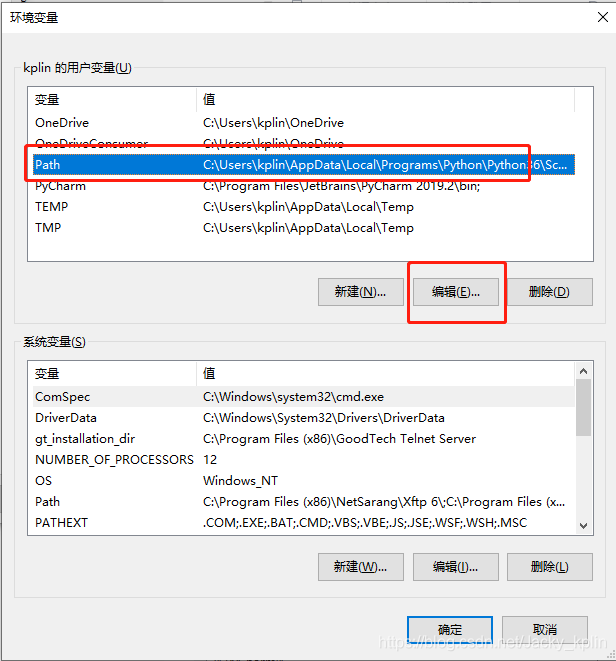
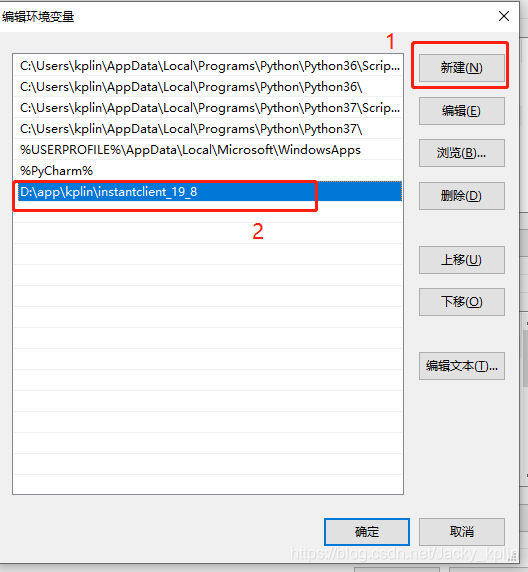
2.4、重启电脑,让新配置的环境变量生效
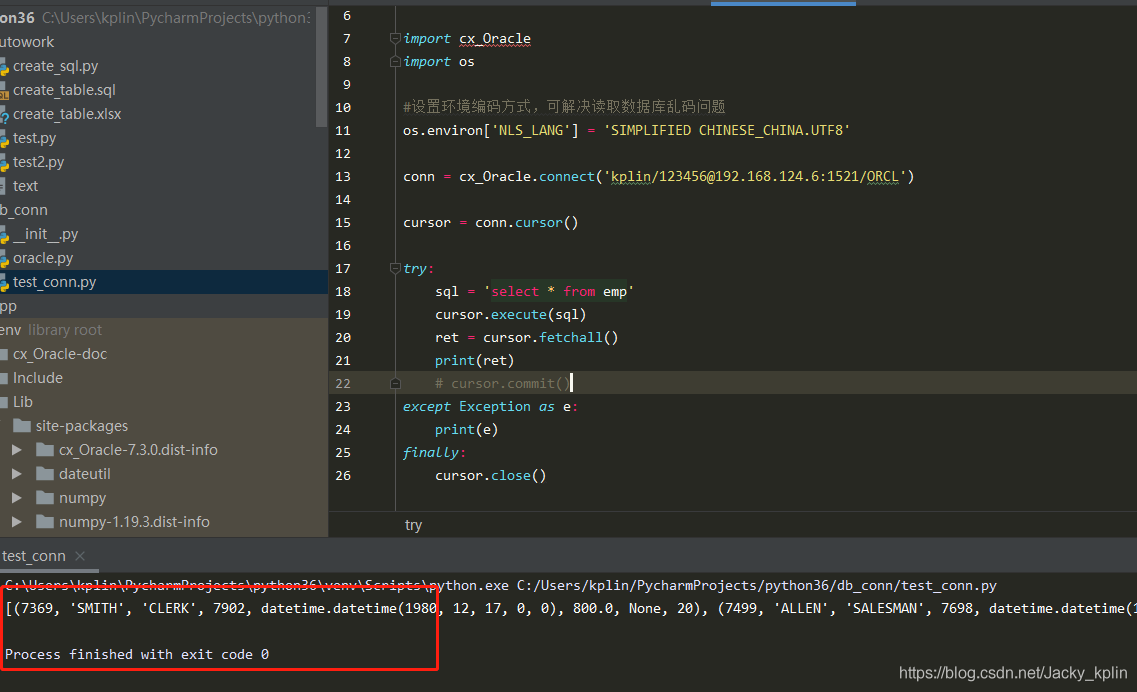
2.5、测试配置是否成功
虽然导入cx_Oracle有红色波浪线,一般认为导入不成功,但这里可以先不管它,直接运行测试代码,没有报错说明没问题。
如果没有查到数据,也可能是该用户下没有emp表。
import cx_Oracle import 操作系统 #,设置环境编码方式,可解决读取数据库中文乱码问题 os.environ [& # 39; NLS_LANG& # 39;],=, & # 39; SIMPLIFIED CHINESE_CHINA.UTF8& # 39; #,用户名/密码@IP:端口/实例名 时间=conn cx_Oracle.connect (& # 39; kplin/12 sss3456@192.168.124.102:1521/orcl # 39;) 时间=cursor conn.cursor () 试一试: 时间=sql 才能;& # 39;select *,得到emp # 39; cursor.execute才能(sql) 时间=ret 才能;cursor.fetchall () 打印(ret)才能 #,才能cursor.commit () except Exception as e: 打印(e)才能 最后: cursor.close才能()
二、使用熊猫读取excel数据,使用sqlalchemy协助写入数据库
1,安装sqlalchemy,熊猫
这里指定熊猫版本是因为最新版的熊猫在读写excel的时候会有些奇怪的报的错,换成1.1.4版本即可。
2,准备一个excel表,命名为测试。xlsx,写入以下测试数据
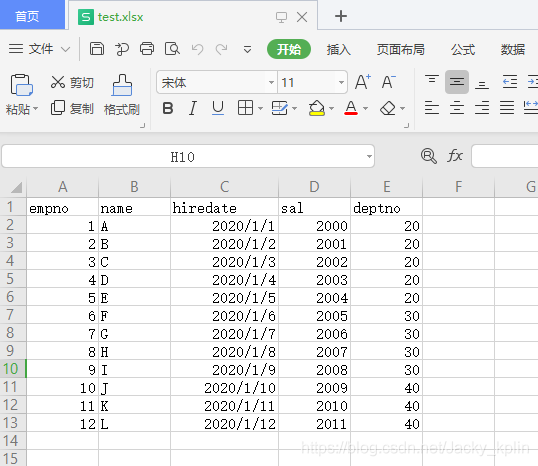
3,测试读取并写入数据库