介绍
本篇文章给大家分享的是有关如何在python中使用jieba中文分词库,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
<强> 1.1,削减函数简介
削减(句子,cut_all=False,嗯=True)
返回生成器,遍历生成器即可获得分词的结果
lcut(句子)
返回分词列表
import jieba
时间=sentence & # 39;我爱自然语言处理& # 39;
#,创建【Tokenizer.cut 生成器】对象
时间=generator jieba.cut(句子)
#,遍历生成器,打印分词结果
时间=words & # 39;/& # 39; . join(发电机)
打印(单词) 打印结果
我/爱/自然语言/处理
import jieba
print (jieba.lcut(& # 39;我爱南海中学& # 39;)) 打印结果
['我& # 39;爱& # 39;,“南海中学& # 39;]
<强> 1.2,分词模式
精确模式:精确地切开
全模式:所有可能的词语都切出,速度快
搜索引擎模式:在精确模式的基础上,对长词再次切分
import jieba
时间=sentence & # 39;订单数据分析& # 39;
打印(& # 39;精准模式:& # 39;,,jieba.lcut(句子)
打印(& # 39;全模式:& # 39;,,jieba.lcut(句子,,cut_all=True))
打印(& # 39;搜索引擎模式:& # 39;,,jieba.lcut_for_search(句子)) 打印结果
精准模式:[“订单& # 39;,“数据分析& # 39;]
全模式:[“订单& # 39;,“订单数& # 39;,“单数& # 39;,“数据& # 39;,“数据分析& # 39;,“分析& # 39;]
搜索引擎模式:[“订单& # 39;,“数据& # 39;,“分析& # 39;,“数据分析& # 39;]
<强> 1.3,词性标注
jieba.posseg
import jieba.posseg as 摩根大通
时间=sentence & # 39;我爱Python数据分析& # 39;
时间=posseg jp.cut(句子)
for 小姐:posseg拷贝:
,打印(i.__dict__)
,#打印(i.word, i.flag) 打印结果
{“词# 39;:”我& # 39;,,的国旗# 39;:" # 39;}
{'字# 39;:'爱& # 39;,,的国旗# 39;:v # 39;}
{'字# 39;:python # 39;,,“国旗# 39;:,”英格# 39;}
{”字# 39;:“数据分析& # 39;,,的国旗# 39;:l # 39;} 词性标注表
标注解释标注解释标注解释一形容词mq数量词tg时语素广告副形词n名词u助词ag形语素ng例:义乳亭ud例:得一名形词nr人名ug例:过b区别词nrfg也是人名uj例:c连的词nrt也是人名ul例:了d副词ns地名紫外线例:地df例:不要nt机构团体是乌斯例:着dg副语素新西兰其他专名v动词e叹词o拟声词vd副动词f方位词p介词vg动语素g语素问量第六词例:沉溺于等同于h前接成分r代词vn名动词我成语rg例:兹vq例:去浄去过唸过j简称略语rr人称代词x非语素字k后接成分rz例:这位y语气词l习用语年代处所词z状态词m数词t时间词zg例:且丗丟 <强> 1.4,词语出现的位置
jieba.tokenize(句子)
import jieba
时间=sentence & # 39;订单数据分析& # 39;
时间=generator jieba.tokenize(句子)
for position 发电机拷贝:
,打印(位置) 打印结果
(“订单& # 39;,,0,,2)
(“数据分析& # 39;,,2,,6) 2,词典
<强> 2.1,默认词典
import jieba,,操作系统,,pandas as pd
#,词典所在位置
打印(jieba.__file__)
时间=jieba_dict os.path.dirname (jieba.__file__), +, " # 39; \ dict.txt& # 39;
#,读取字典
df =, pd.read_table (jieba_dict, 9=& # 39;, & # 39;,,头=None) ((0, 2))
print (df.head ())
#,转字典
时间=dt dict (df.values)
print (dt.get(& # 39;暨南大学& # 39;)) <强> 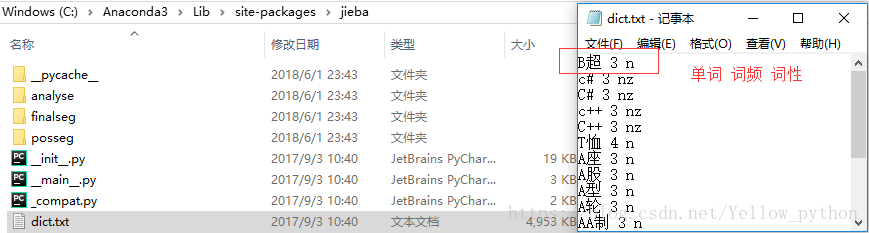 import jieba
时间=sentence & # 39;天长地久有时尽,此恨绵绵无绝期& # 39;
#,添词
jieba.add_word(& # 39;时尽& # 39;,,999,,& # 39;新西兰# 39;)
打印(& # 39;添加【时尽】:& # 39;,,jieba.lcut(句子)
#,删词
jieba.del_word(& # 39;时尽& # 39;)
打印(& # 39;删除【时尽】:& # 39;,,jieba.lcut(句子))
import jieba
时间=sentence & # 39;天长地久有时尽,此恨绵绵无绝期& # 39;
#,添词
jieba.add_word(& # 39;时尽& # 39;,,999,,& # 39;新西兰# 39;)
打印(& # 39;添加【时尽】:& # 39;,,jieba.lcut(句子)
#,删词
jieba.del_word(& # 39;时尽& # 39;)
打印(& # 39;删除【时尽】:& # 39;,,jieba.lcut(句子))
打印结果
添加【时尽】:[‘天长地久& # 39;,“有& # 39;,“时尽& # 39;,“,& # 39;,“此恨绵绵& # 39;,“无& # 39;,“绝期& # 39;]