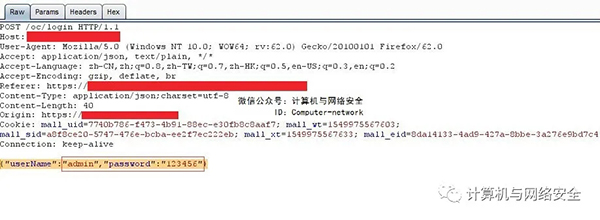
一、urlparse模块简介
二,urljoin函数使用
,,,, urljoin主要是拼接url,它以基地作为其基地址,然后与url中的相对地址相结合组成一个绝对url地址。函数urljoin在通过为url基地址附加新的文件名的方式来处理同一位置处的若干文件的时候格外有用。需要注意的是,如果基地址并非以字符/结尾的话,那么url基地址最右边部分就会被这个相对路径所替换。如果希望在该路径中保留末端目录,应确保url基地址以字符/结尾。
输入代码:
import urlparse # urljoin函数是合并域名和相对路径的 时间=urljoin urlparse.urljoin (“http://www.sina.cn/cc”,“文件/down.php”) print urljoin 时间=urljoin1 urlparse.urljoin (“http://www.sina.cn/cc/?“文件/down.php”) print urljoin1
代码运行结果:
C: \ Python27 \ python。exe C:/用户/李/桌面/d/PycharmProjects/untitled/test.py http://www.sina.cn/file/down.php
http://www.sina.cn/cc/file/down.php
三,urlparse函数和urlsplit函数使用
,,主要是分析urlstring,返回一个包含5个字符串项目的元组:协议,位置,路径,查询,片段.allow_fragments为假时,该元组的组后一个项目总是空,不管urlstring有没有片段,省略项目的也是空.urlsplit()和urlparse()差不多
输入代码:
代码运行结果:
C: \ Python27 \ python。exe C:/用户/李/桌面/d/PycharmProjects/untitled/测试。py
SplitResult(计划=癶ttp”netloc=' www.baidu.com ',路径='/好/索引。php”,查询=' id=18”,片段=")
www.baidu.com http
/好/index . php
id=18