? ?信息加密技术经过多年的发展,由一些基本算法组合形成了许多成熟的应用,如数字签名,安全证书,HTTPS,以及最近大热的数字加密货币,区块链等。这些看似种类繁多的应用,其实都由三类基本的算法通过不同的组合来实现,这三类算法分别是:数据摘要(在很多场合也被称作哈希运算),对称加密,非对称加密。本文抛开这三类算法在不同实现方案中的差异,抽象出各类算法的共性,提纲挈领地描绘出三类算法在加密体系中的应用场景,让开发者能在短时间内对信息加密体系有个全局的认识,并能将这三类算法应用在实际的需求场景中,希望本文能成为设计信息加密应用的简要手册。
? ?阅读建议:每类算法都以伪代码给出函数声明,不代表特定算法,比如函数消化代表了在实际使用中的MD5、SHA1, RIPEMD160等实现了数据摘要功能的算法,读者在阅读过程中不要急于去考虑这些函数的实现,而应该去领会算法的特点和完成的功能,这些算法几乎在所有主流的编程语言库中都有具体实现,实在有很少的场合需要自己再去实现。对于有研究技术细节需求的读者,可以在阅读完本文后,对信息加密体系这棵树有了全局的了解,再按图索骥地去研究树叶。
? ?下面将分别介绍这三类算法各自的特性和应用,然后再对将这些算法组合起来的应用进行介绍。
? ?
1。数据摘要
1.1。函数声明:
<代码类="语言java "> byte[]消化(byte[]数据)
1.2。函数特性:
? ? 1.2.1。无论数据的长度为多少,消化返回某一定长数据,通常为几十个字节
? ? 1.2.2。若消化(data1) !=消化(data2),则data1 !=data2;若消化(data1)=消化(data2)则可以认为有很高的概率data1=data2,在特定的情况下,对某些算法来讲,该判断出错的概率不到1/128 ^ 2。
? ? 1.2.3。运算不可逆,即知道消化的返回值,不能反推出数据的值。顺便提一句,人们常提起的比特币挖矿其实就是指通过不断的尝试找出一个数据,使得消化(数据)的结果小于某一个表示难度的数,其基本代码如下:
<代码类="语言java ">,(消化(blockData +随机())比;difficultyFactor);//随机()在这里产生随机数
? ?可见即使为了得到满足某一条件的数据值,也只能通过暴力尝试,而不能有其它快速的方法。
? ? 4。消化函数相对于下面要谈的其它两类算法来说,运算速度非常快。注意是相对的快,因为即便如此挖矿也是个很费时的运算,呵呵。
1.3。应用举例:
1.3.1。大数据检索比较
? ?假设要做这么一个文件上传系统,要求上传文件前,先检测服务器上是否已经有同样的文件存在,如果已经存在,则不再上传。如果没算有消化法,只有把整个文件上传到服务器再进行比较,这无疑非常费时。如果我们每次上传文件,都对文件做一次摘要运算(特性1.2.4 :摘要运算速度非常快,相对于文件上传的耗时来说忽略不计),并将摘要值保存起来,那么下次上传文件前我们对将要上传的文件进行一次摘要运算,只是把摘要值提交到服务器(特性1.2.1 :摘要值一般只有几十个字节),服务器在之前保存的摘要值列表中查找客户端新提交上来的摘要值,如果找到了(特性1.2.2 ),则告诉客户端不用再上传了。这就是很多云盘使用的秒传技术,很多上G的文件,只要几秒钟就上传成功了,原因就在于其他人在你之前已经上传过同样的文件。
1.3.2。防数据损坏
? ?还是上传文件的例子,客户端上传前先把本地文件的摘要值传给服务器,服务器在接收到完整的文件后,用同样的摘要算法,计算接收到的文件的摘要值,和客户端上传的摘要值进行比较,如果相同则可以认为文件接收完整;反之则认为文件在传输过程中损坏(特性1.2.2 )。
1.3.3。防数据纂改
? ?设计一个简单的充值磁条卡,所有磁卡机都能读磁卡中的数据,但只有授权的磁卡机才能合法地写入数据。其数据写入的过程如下图所示:
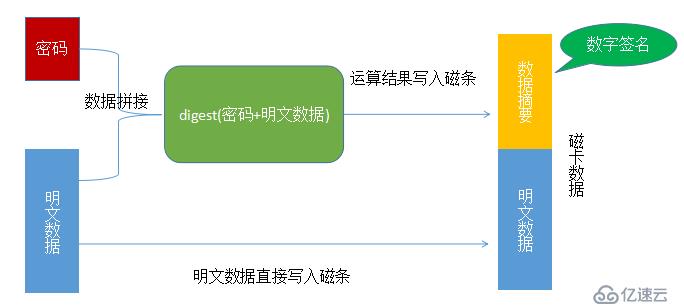 构成信息安全技术体系的三类基本算法
构成信息安全技术体系的三类基本算法