介绍
8。官网读取JDBC数据注意一定要加司机属性
这篇文章主要介绍“火花SQL外部数据源的机制以及spark-sql的使用”,在日常操作中,相信很多人在火花SQL外部数据源的机制以及spark-sql的使用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答“火花SQL外部数据源的机制以及spark-sql的使用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
一。数据解释与杂项
1。外部数据源API,外部数据源
4.包
——packages ,优点,灵活,给你都拉去过来本地有的,没有的才下载的,,,
缺点:生产中集群不能上网,maven没用
解决办法:有——jars ,,,打成jar包传上去
 5。内部内置与外部数据源
5。内部内置与外部数据源
json.vsv, hdfs,蜂巢,jdbc、s3,拼花,,redis 等 分为两大类,build-in (内置),,,3 th-party(外部) spark.read.load(),,默认读的是镶花文件
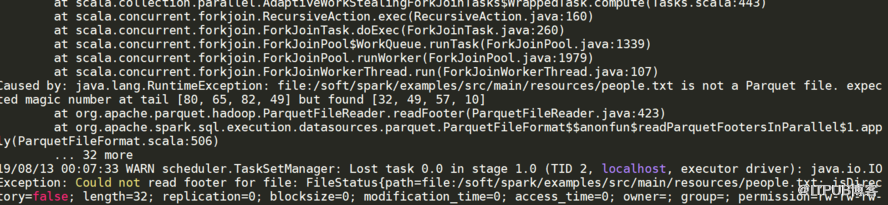 6。外部添加jar包和使用实例
6。外部添加jar包和使用实例
csv为例使用https://spark-packages.org 这个网址 点主页
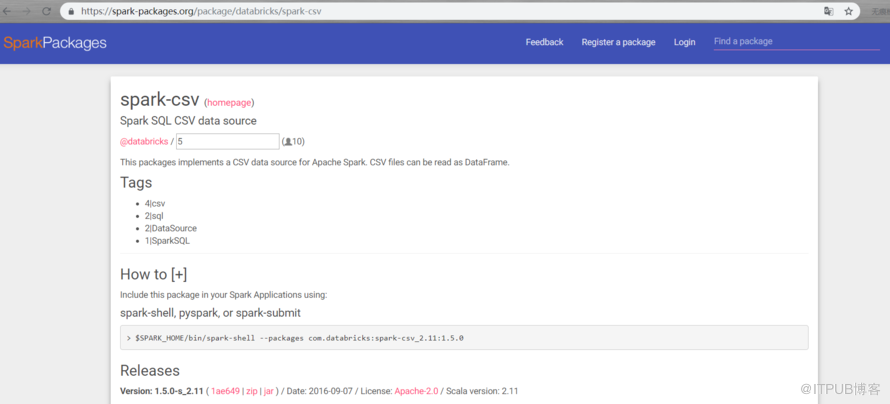 7。读写标准写法
7。读写标准写法
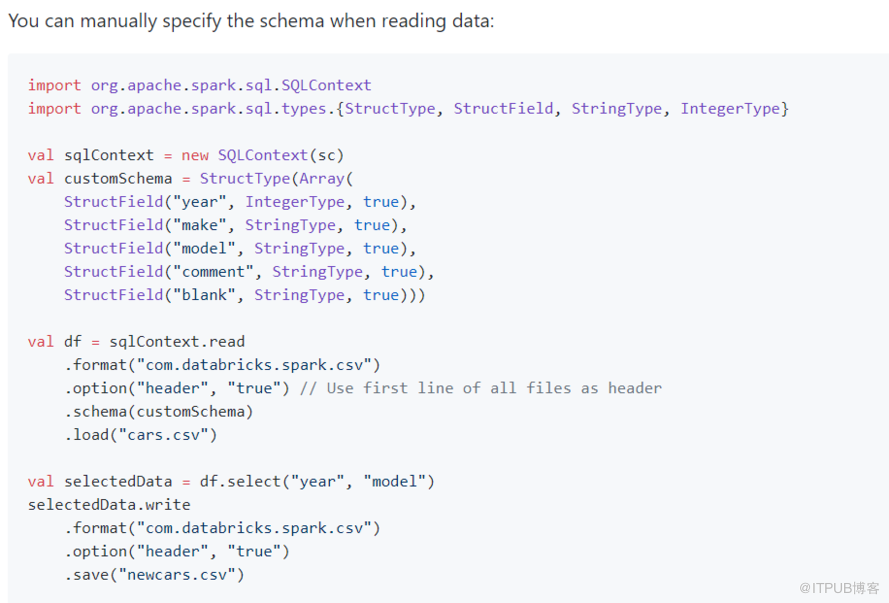
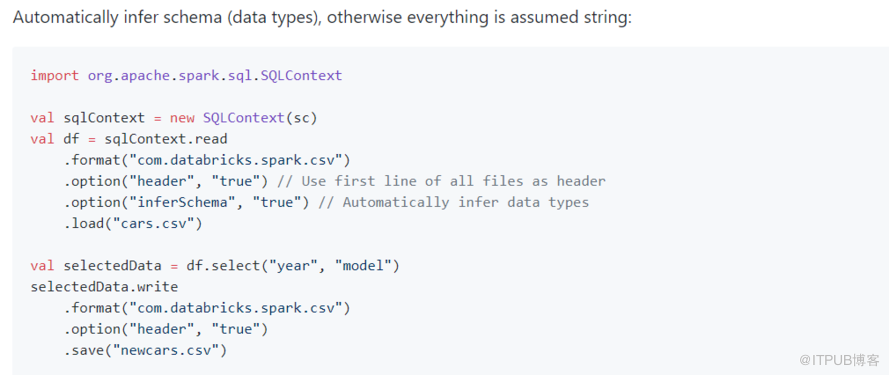 8。自定义约束条件
8。自定义约束条件
 9。支持数组等其他复杂类型像蜂巢
9。支持数组等其他复杂类型像蜂巢
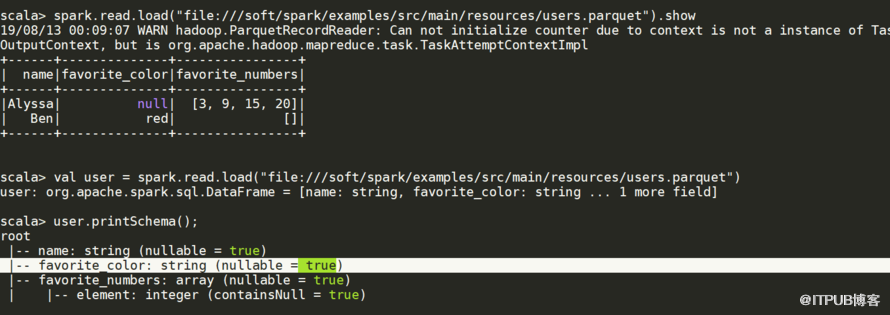 二。JDBC读写问题
二。JDBC读写问题
1。写入时文件存在问题(已经存在)
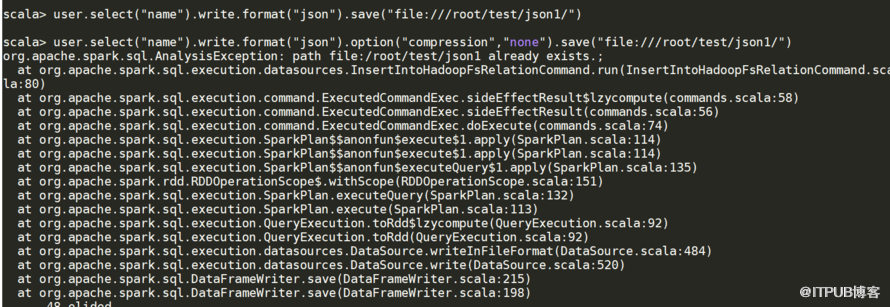 2。解决方式官网,加载文件数据 <>之前存在抛出异常
目标存在追加,但是重跑一次可能两份,有弊端(保证不了每次处理都是一样的)
目标表存在,已经存在的数据被清掉
忽略模式,有了就不会再往里加了
2。解决方式官网,加载文件数据 <>之前存在抛出异常
目标存在追加,但是重跑一次可能两份,有弊端(保证不了每次处理都是一样的)
目标表存在,已经存在的数据被清掉
忽略模式,有了就不会再往里加了
 3。想看到你写的文件内容可以不压缩
3。想看到你写的文件内容可以不压缩
user.select (“name") .write.format (“json") .option (“compression",“none") .save(“文件:///根/测试/json1/? ,user.select (“name") .write () .format (“json") .save(“/根/测试/json1/?
5。savemode是枚举类型,java类,
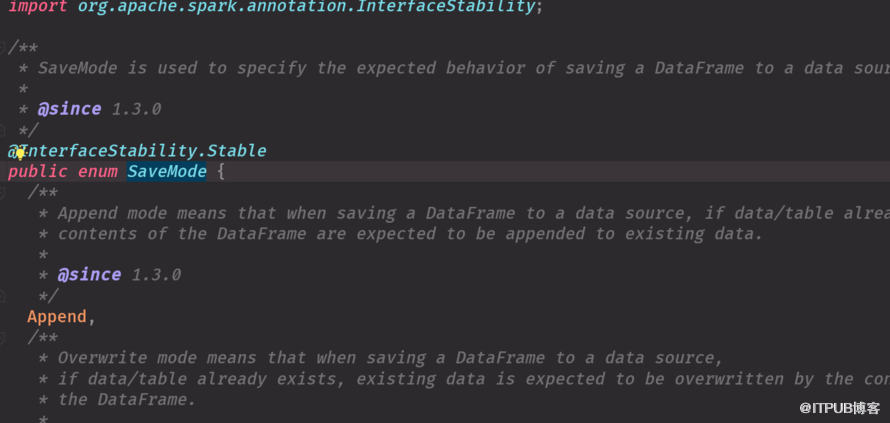 6。效果一样
6。效果一样
result.write.mode (“default") result.write.mode (SaveMode.ErrorIfExists)