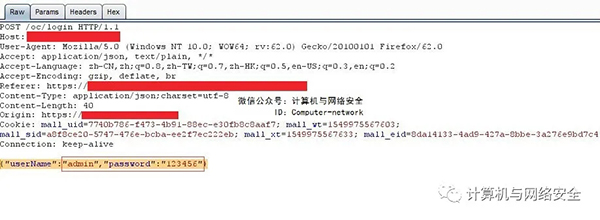
,类型key_name:查看某个关键是什么类型的
,在帮助@STRING #查看字符串类型的帮助
,设置键值(前| NX | XX):设定一个键值
,,例表示过期时间,单位是s
,存,NX表示当此关键在时不创建,如果不存在则创建
,存,XX表示当此关键在时修改
,setnx:当指定关键不存在才创建
,mset:一次设置多个关键
,得到:获取某个键的值
,mget:一次获取多个键的值
,getset:设定指定关键新值的同时,返回指定关键的原值
,附加:在指定键的值后边追加新的内容
,德尔:删除某个关键
,存在:判断某关键是否存在,存在返回1,不存在返回0
,strlen:返回某关键的长度
,键*:查看所有的关键
,增加:自动加1
,12月:自动减1
,字符串类型的关键,不支持增加,12月的操作
,在帮助@ list #查看列表类型的帮助
,lpush:从左边开始往关键中加入数据
,lpop:从左边开始往外弹出数据
,rpush:从右边开始往关键中加入数据
,rpop:从右边开始往外弹出数据
,llen:查看指定列表的长度
,lrange:取出指定关键的数据范围
,lindex:取出指定列表的指定下标的值,例:lindex l1 0,取出列表l1的第1个值
,ltrim:保留指定范围内的数据
,lset:修改指定索引的值为指定的值
<强>
,在帮助@set #查看无序集合类型的帮助
,大块漂浮植物:向集合中添加数据
,spop:随机弹出一个元素
,srem:从集合中删除一个已知的值(不是随机弹出)
,scard:统计一个集合中有多少个值
,smembers:查看集合中的所有数据
,sismember:判断指定数据在集合中是否存在,在0表示不存在,1表示存在
,烧结矿(交集):显示两个集合间的交集,即两个集合同时存在的数据
,sunion(并集):显示两个集合去除重复后的全部数据
,sdiff(差集):显示前边的集合与后边集合间的差集
,smove:移动一个集合的值到另一个集合
,在帮助@sorted_set #查看有序集合类型的帮助
,zadd:向集合中添加一个元素,可以同时指定多个值;同时要给此元素打一个分数(因为sorted_set是依靠分数来进行排序的,分数放在值的前边)
,例:祝辞zadd工作日1星期一,2,星期二(我的得分是1,星期二的得分是2)
,zcard:获取有序集合中的成员个数
,zrank:获取有序集合中某元素的索引
,zscore:查看元素的分数
,zrange:返回指定索引范围的数据
,在帮助@hash #查看哈希类型的命令帮助
,hset:设置指定关键的字段值
,,用法:hset关键字段值
,hsetnx:当指定关键不存在时才进行设置
,hget:获取指定字段的值
,,用法:hget关键字段
,hdel:删除指定关键的指定字段
,hlen:获取指定关键字段的个数
,, hmset:一次设置多个字段
,hmget:一次获取多个字段值
,hexists:判断指定关键中某个字段是否存在
,hkey:获取所有的字段名字
,hvals:获取所有字段的值
,hgetall:获取指定关键的所有字段和值
,hyperloglog类似于集类型,但比设置类型节省内存;
,hyperloglog可以利用极小的内存空间完成独立总数的统计,但存在一定的误差率
,添加hyperloglog数据:
,,祝辞pfadd 2016 _03_06:独特:id“uuid-1”“uuid-2”“uuid-3”“uuid-4”
,,祝辞pfadd 2016 _03_07:独特:id“uuid-4”“uuid-5”“uuid-6”“uuid-7”,
,统计hyperloglog有多少条数据:
,,在2016年pfcount _03_07:独特:id
,求2个或者多个hyperloglog的并集:
,,语法:PFMERGE destkey sourcekey [sourcekey…]
,,祝辞pfmerge联盟2016 _03_06:独特:id 2016 _03_07:独特:id
,使用前需要确定:
,,1 .只为计算独立总数,不需要获取单条数据
,,2.可以容忍一定的误差率,毕竟hyperloglog在内存上占用量上有很大的优势