1,谷歌黑客
svn搜索技巧,
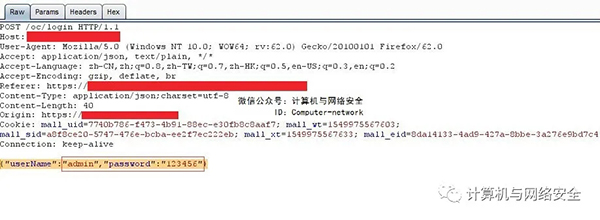
图1,
git搜索技巧,
图2
2, svn信息利用原理
2.1 svn<=1.6
从svn的结构图可以看到一个目录支持,这里有我们源文件的备份,比如要下载到phpinfo . php, somedomain/直接访问目录somedomain/. svn/支持/phpinfo.php.text-base,一般的服务器既不会阻止该目录也不会解释该后缀,我们就可以直接读到本地来。现在只是访问最顶层的文件信息,那怎么遍历呢?这里面就有。svn/条目,这个文件包含着该基础目录下所有的文件和目录,直接递推查找就行。
2.2 svn> 1.6
1.6 svn在之后引入了wc.db来管理文件,该文件位于. svn/wc.db。普通文件位置:somedomain/. svn/原始/癤X”/靶Q楹汀?svn-base,校验和是文件的sha1值,XX则是他的前两位。那这个校验和去哪找呢?就是我们刚才提到的wc。数据库,这是一个sqlite数据库。数据库的大体结构如下:
<代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
第一步下载wc。db,然后从节点表中找到文件名和其sha1值,最后构造下载链接。
3, git信息利用原理
首先从git/配置信息里面可以得到仓库地址
<代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
<李><代码>
基本上三步走:,
(1)下载./索引文件,这是一种git特有的格式,在该文件中包含着文件名和文件sha1值只
(2)根据该文件sha1值到对象目录下载相应文件,具体路径somedomain/./对象/癤X”/靶Q楹汀?
(3) zlib解压文件,按照原始目录写入源代码。
4,对国内80端口的简单扫描
有了前面这些基础,就可以通过泄漏的信息来还原代码,能还原代码的话就可以干很多事了。最常见就是代码中泄漏邮件地址,数据库连接方式,调试接口,一些第三方关键的泄漏。另外还可以对你感兴趣的目标进行代码审计,发现注入,命令执行等等。
4.1扫描实现
(1)从文件读取80个ip段数据,设最大并发16日最大连接数60,这个时候的带宽基本控制在600 kb,利用周末时间跑了一天即可跑完只
(2)设置pycurl的一些参数,如代理,MAXREDIRS=0,这样就不跳转了,nosignal=1这个参数必须为1,这是pycurl的一个bug,中间测试的过程中就是因为参数未加,导致跑了半天结果中途挂了只
(3)请求/./配置信息,如果200年返回的类型为text/平原并且存在repositoryformatversion字段。请求/. svn/条目,如果200年,内容类型为text/平原,并且dir存在于返回值。其实这个是有误的,因为在svn大于1.6的情况下,在返回值中只有一个简单的数字,并不存在dir,所以扫描结果中基本上没有1.6以上的结果。
4.2结果过滤
在扫描的结果中分析出现的url,有些。svn/条目返回200年,但是首页确是有问题,还有发现某些ip不在中国。于是写了脚本去请求这些url的首页,并且从一个ip查询网站去查询ip地址归属。
4.3初步结果
在525年万80年端口数据中,跑出6000条结果,相当于千分之一的概率,另外还未包括前面对svn 1.6判断有误的分析,所以这个概率还是很高的只
简单的分析了git信息的泄漏,总共有接近600条数据,去除在国外的和首页不正常的,能达到250多,其中差不多一半的都是在阿里云的ip上,这些公司一般都是创业公司。在这些泄漏的代码中sql注入一般很少只
svn的话,一般都是一些比较老的网站,这主要可能还是我前面的判断逻辑有点小问题。注入问题比较严重。