这篇文章主要介绍“Kafka的原理及单机部署方式”,在日常操作中,相信很多人在Kafka的原理及单机部署方式问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Kafka的原理及单机部署方式”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
一、kafka介绍及原理
kafka是由Apache软件基金会发布的一个开源流处理平台,由Scala和Java编写。它是一种高吞吐量的分布式发布的订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
1、kafka的特性
kafka是一种高吞吐量的分布式发布订阅消息系统,具有以下特性:
通过磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能;
持久性:使用文件性存储,日志文件存储消息,需要写入硬盘,采用达到一定阈值才写入硬盘,从而减少磁盘I/O,如果kafka突然宕机,数据会丢失一部分;
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数百万的消息;
支持通过kafka服务器和消费机集群来分区消息;
支持Hadoop并行数据加载。
2、kafka相关术语
Broker:消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群;
Topic:Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic;
Producer:消息生产者,向Broker发送消息的客户端;
Consumer:消息消费者,从Broker读取消息的客户端;
ConsumerGroup:每个Consumer属于一个特定的Consumer Group,一条消息可以发送到多个不同的Consumer Group,但是一个Consumer Group中只能有一个Consumer能够消费该消息;
Partition:物理上的概念,一个topic可以分为多个partition,每个partition内部是有序的。
3、Topic和Partition的区别
一个topic可以认为一个一类消息,每个topic将被分成多个partition,每个partition在存储层面是append log文件。任何发布到此partition的消息都会被追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为long型的数字,它唯一标记一条消息。每条消息都被append到partition中,是顺序写磁盘,因此效率非常高(顺序写磁盘比随机写内存的速度还要高,这是kafka高吞吐率的一个很重要的保证)。
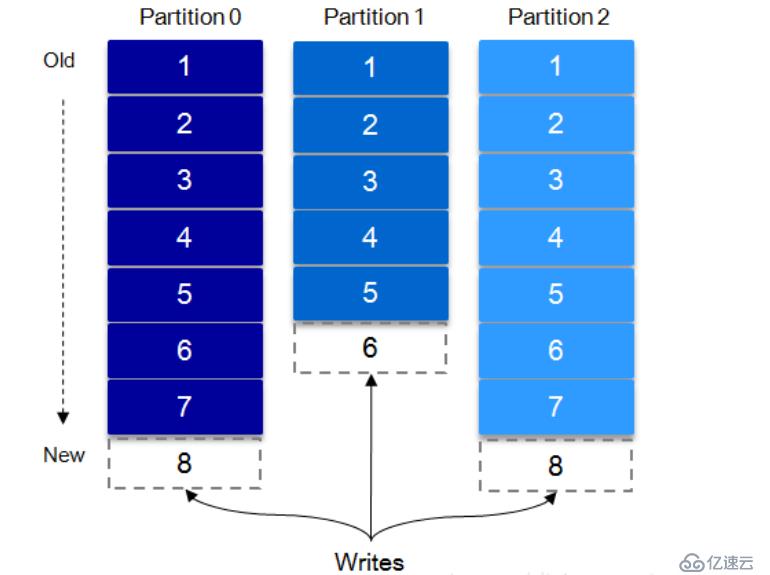
每一条消息被发送到broker中,会根据partition规则选择被存储到哪一个partition(默认采用轮询的方式进行写入数据)。如果partition规则设置合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题),如果消息被消费则保留append.日志两天。
4,卡夫卡的架构
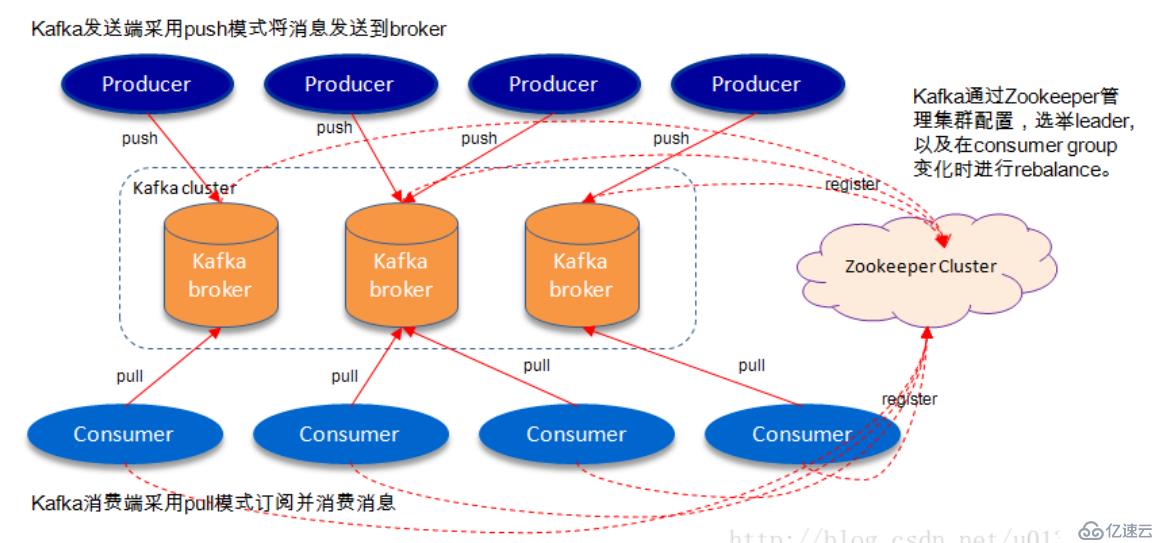
如上图所示,一个典型的卡夫卡体系架构包括若干生产商(可以是服务器日志,业务数据,页面前端产生的页面视图等),若干个代理(卡夫卡支持水平扩展,一般代理数量越多,集群吞吐率越高),若干消费者(集团),以及一个饲养员集群.kafka通过动物园管理员管理集群配置,选举出领袖,以及在消费者团体发生变化时进行重新调整.Producer使用推(推)模式将消息发布到经纪人,消费者使用拉(拉)模式从代理订阅并消费消息。
管理员群集中有两个角色:领袖和追随者,领导对外提供服务,追随者负责领袖里面所产生内容同步消息写入生成时产生副本(副本),
卡夫卡的高可靠性的保证来源于其健壮的副本(副本)策略。通过调节其副本相关参数,可以使得卡夫卡在性能和可靠性之间运转之间的游刃有余.kafka从0.8。x版本开始提供分区级别的复制的。