这篇文章主要讲解了“蜂巢数据倾斜的原因及优化方法”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“蜂巢数据倾斜的原因及优化方法”吧!
<强>数据倾斜成因:由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。具体为某一个减少接收到的数据是其他减少的n倍,导致明显的木桶效应。
<强>症状:
1,对表做选择从结核病组数(1)键,看表中是否有大量相同的关键。
2,查看监控界面,任务进度长时间维持在99%(或100%),只有少量(1个或几个)减少子任务未完成或某几个减少子任务是平均减少时长的n倍;
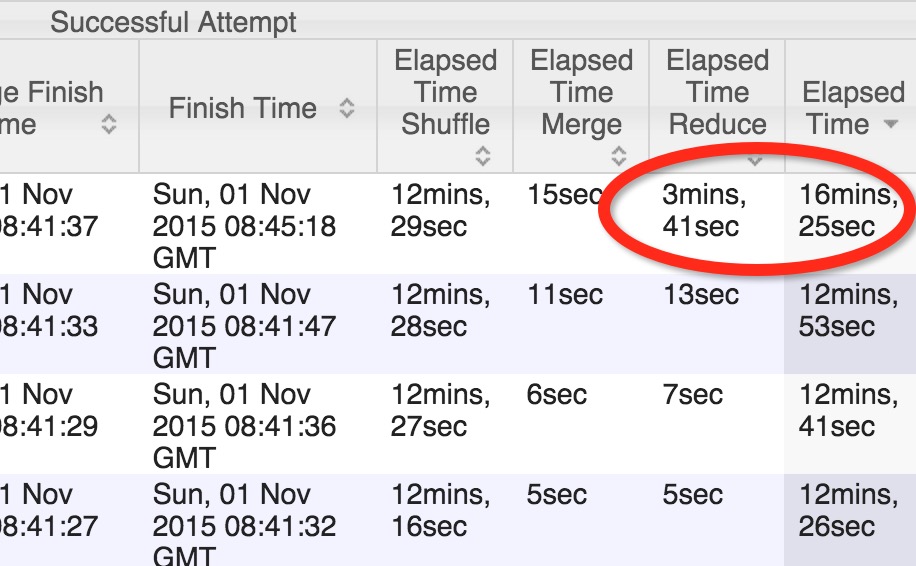
上图的其中的一个工作的减少时间远远超出其他减少时长,表明该减少处理的数据远超出其他的减少,可见此次统计发生数据倾斜。
<强>解决方案
<强>参数调优:
<强> 1,设置hive.groupby.skewindata=https://www.yisu.com/zixun/true 这个参数的意思是做减少操作的时候,拿到的关键并不是所有相同值给同一个减少,而是随机分发,然后减少做聚合,做完之后再做一轮先生,拿前面聚合过的数据再算结果,所以这个参数其实跟Hive.Map.aggr做的是类似的事情,只是拿到减少端来做,而且要额外启动一轮工作,所以其实不怎么推荐用,效果不明显。
<强> 2,设置hive.skewjoin。关键=100000:这个是加入的键对应的记录条数超过这个值则会进行优化。
<强> 3,设置mapred.reduce。任务=500:强增加减速机个数,通常数据(KV数值对)转移到某个减速器是根据关键进行哈希然后对减速器个数进行取模。
<强> HQL语句优化:
1,小表加入大表:
将小表放在加入左边,减少伯父的几率;
使用mapjoin,小表数据最好在1000条以内.select/* + mapjoin (a) */计数(1)从tb_a左外连接tb_b b>感谢各位的阅读,以上就是“蜂巢数据倾斜的原因及优化方法”的内容了,经过本文的学习后,相信大家对蜂巢数据倾斜的原因及优化方法这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是,小编将为大家推送更多相关知识点的文章,欢迎关注!