
介绍 <李> <节> <强> RabbitMQ :一个队列,多个消费者。比如,生产者向RabbitMQ里发送了三条数据,顺序依次是data1/data2/data3,压入的是RabbitMQ的一个内存队列。有三个消费者分别从MQ中消费这三条数据中的一条,结果消费者2先执行完操作,把data2存入数据库,然后是data1/data3。这不明显乱了。 <人物> 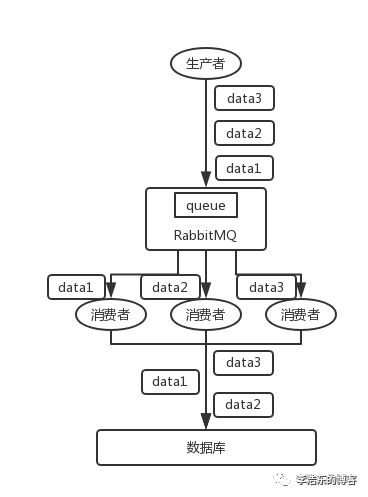 <李> <节> <强>卡夫卡:比如说我们建了一个话题,有三个分区。生产者在写的时候,其实可以指定一个键,比如说我们指定了某个订作单id为键,那么这个订单相关的数据,一定会被分发到同一个分区中去,而且这个分区中的数据一定是有顺序的。
,,
<李> <节> <强>卡夫卡:比如说我们建了一个话题,有三个分区。生产者在写的时候,其实可以指定一个键,比如说我们指定了某个订作单id为键,那么这个订单相关的数据,一定会被分发到同一个分区中去,而且这个分区中的数据一定是有顺序的。
,,
消费者从分区中取出来数据的时候,也一定是有顺序的。到这里,顺序还是ok的,没有错乱。接着,我们在消费者里可能会搞 ,,<强>多个线程来并发处理消息强。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十女士,那么1秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。 <人物>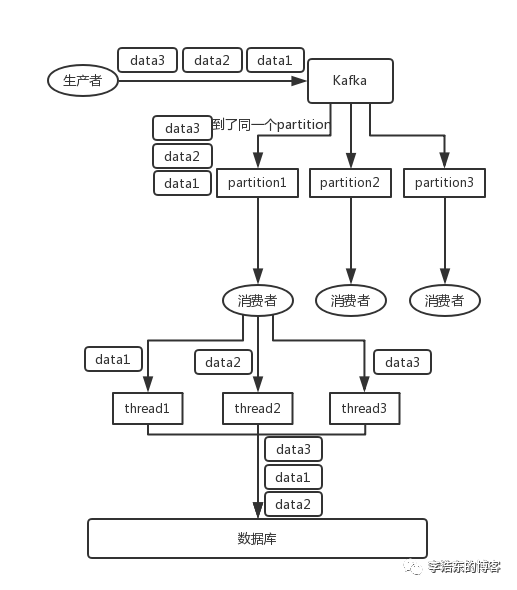 ,
, <李> <节>一个话题,一个分区,一个消费者,内部单线程消费,单线程吞吐量太低,一般不会用这个。 <李> <节>写N个内存队列,具有相同关键的数据都到同一个内存队列,然后对于N个线程,每个线程分别消费一个内存队列即可,这样就能保证顺序性。 <人物> 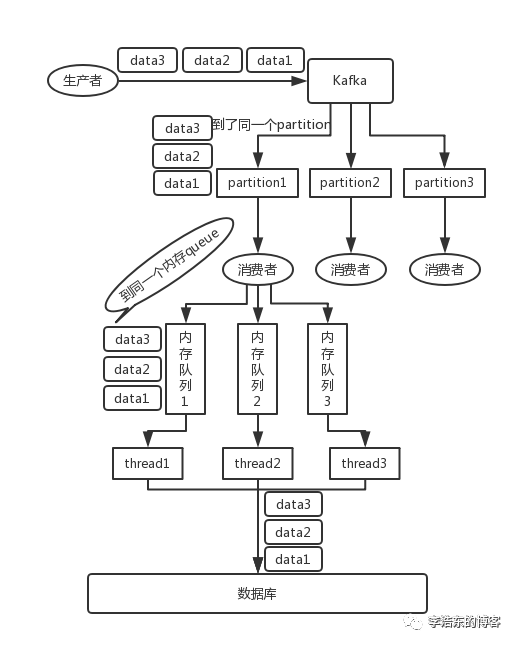 rabbitmq如何保证消息的顺序性
rabbitmq如何保证消息的顺序性
本篇内容介绍了“rabbitmq如何保证消息的顺序性”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
<节>,我举个例子,我们以前做过一个mysql <代码> binlog>
你在mysql里增删改一条数据,对应出来了增删改3条<代码> binlog 日志,接着这三条<代码> binlog>
本来这个数据同步过来,应该最后这个数据被删除了;结果你搞错了这个顺序,最后这个数据保留下来了,数据同步就出错了。
先看看顺序会错乱的俩场景:
<李> <节> <强>卡夫卡:比如说我们建了一个话题,有三个分区。生产者在写的时候,其实可以指定一个键,比如说我们指定了某个订作单id为键,那么这个订单相关的数据,一定会被分发到同一个分区中去,而且这个分区中的数据一定是有顺序的。
,,消费者从分区中取出来数据的时候,也一定是有顺序的。到这里,顺序还是ok的,没有错乱。接着,我们在消费者里可能会搞 ,,<强>多个线程来并发处理消息强。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十女士,那么1秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。 <人物>
, 卡夫卡
rabbitmq如何保证消息的顺序性




