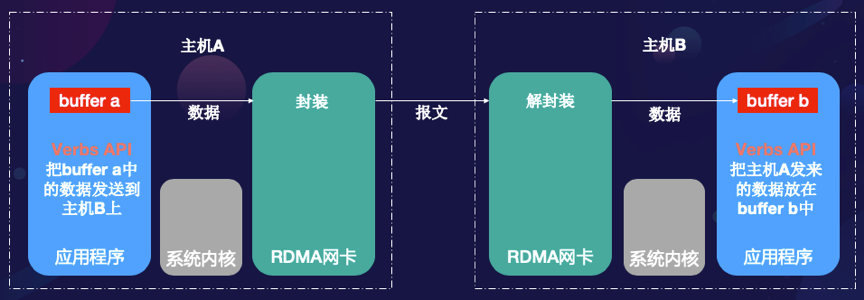
:
大数据集群,只能运行在Linux平台
RDBMS:表
字段,数据类型,约束
结构化数据
关系数据库在数据中占据重要的地位
但不是所有的数据都可以结构化
结构化数据:结构化数据
非结构化数据:非结构化数据
半结构化数据:半结构化数据
通常保存为xml、json
谷歌:pagerank页面算法
化整为零,并行处理
将一个大问题切割成多个小问题
OLAP:数据挖掘
机器学习:深度学习
多节点并行处理
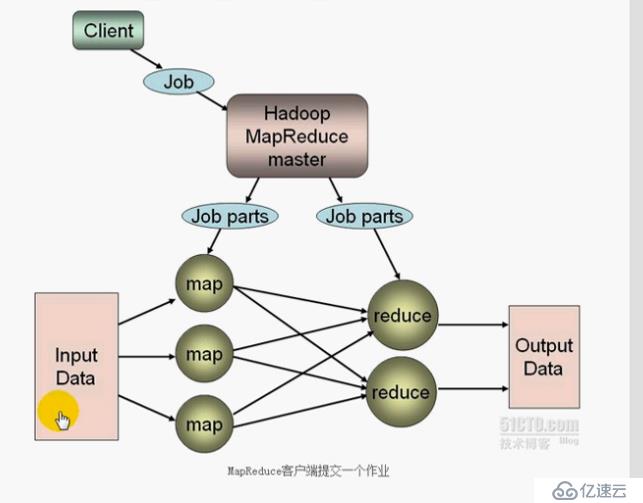
地图减少:
函数式编程API
运行框架
HDFS + Hadoop Mapreduce=
HDFS:
namenode: NN节点
Datanode: DN节点Mapreduce
:
jobTracker: JT节点
TaskTracker: TT节点
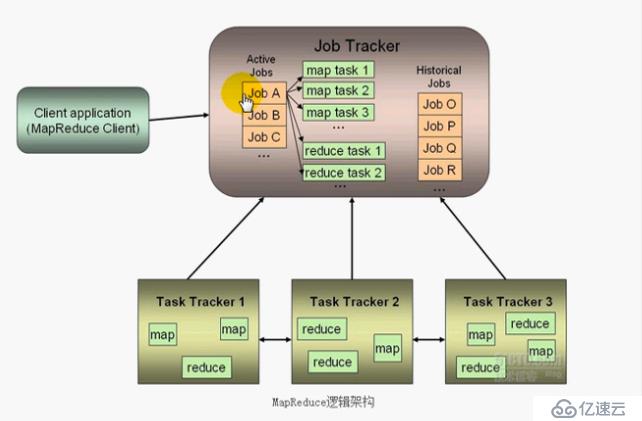
Hadoop使用Java语言开发,映射器,减速机都是使用Java语言开发
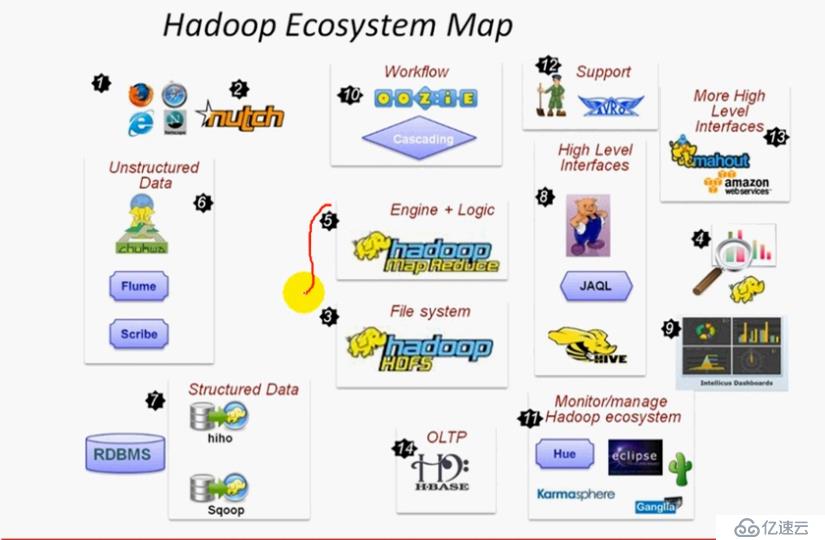
hadoop生态:
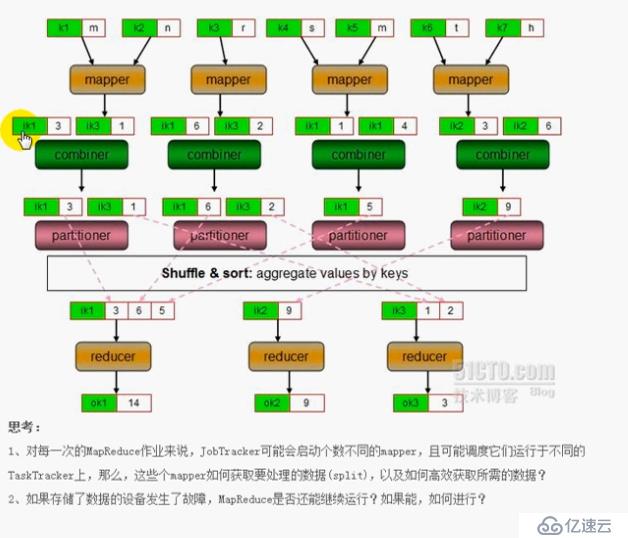
一个映射器,减速机可以没有减少,但不能没有mapper
HDFS:
1, HDFS设计用来存储大文件,对海量小文件的存储不太适用;
2,用户空间的文件系统;
3, HDFS不支持修改,新版本支持追加;
4,不支持挂载,并通过系统调用进行访问,只能使用专用访问接口,如专用命令行工具,API;
文士,facebook
水槽
hadoop外围组件
hadoop集群生态、生态圈
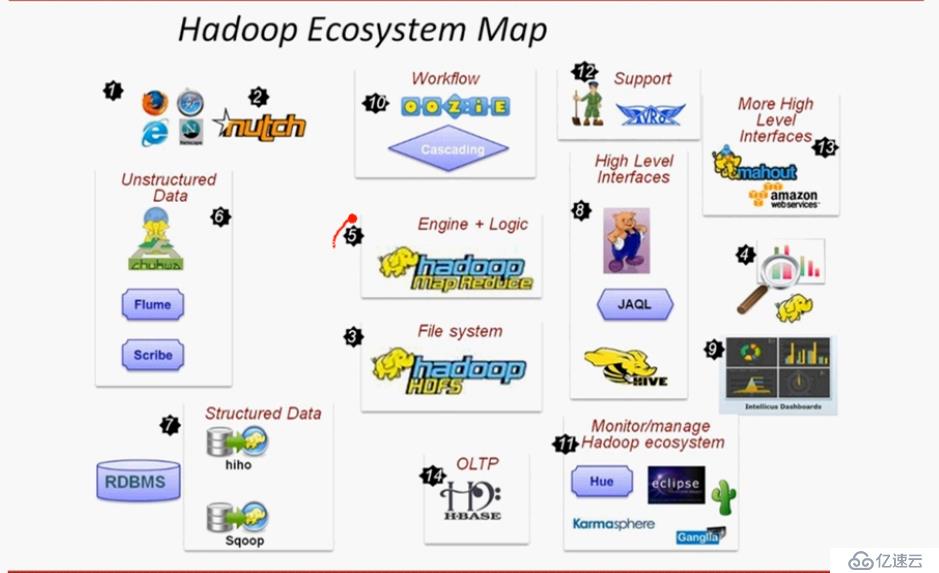
蜂巢中间组件
技术是面向场景的
基于HBASE可以做数据修改
HBASE是NoSQL、稀疏格式存储方案
Cloudera,鼎晖著名hadoop技术服务提供商类似于redhat
关系型数据库数据导入到Hadoop流程图:
RDBMS——比;Sqoop——比;Hbase——比;HDFS
Avro:将数据序列化
如何学习Hadoop
1,安装配置HDFS
2,安装配置MapReduce
3, HBase
4,蜂巢
5, sqoop
6,水槽/抄写员/chukwa
HDFS正常情况几个节点:四个节点
本地模式调试模式
伪分布式(使用一个节点)
完全分布式(4以上的节点)
Hadoop并行处理系统多副本
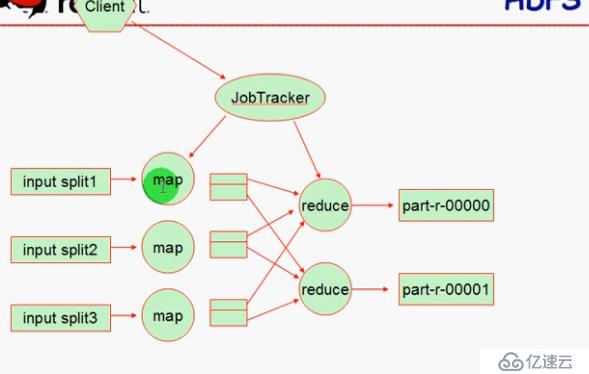
MapReduce
处理逻辑
关系数据库:
行式数据库、表
HBase:
列式数据库
键值对,键值组
收集日志的工具
水槽(ASF)
chukwa (ASF)
抄写员(facebook)
比hadoop更高级的编程接口读入工具
蜂巢SQL
猪
紧缩Java API

Avro序列化工具
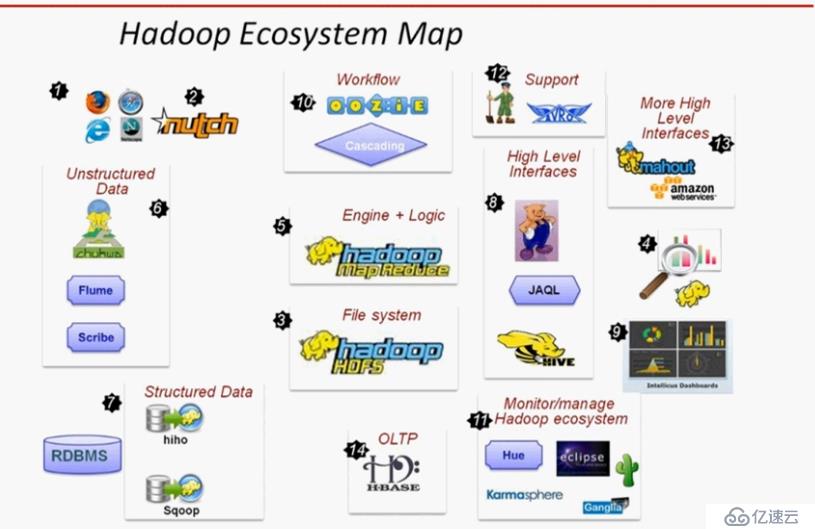
Hadoop有强大的生态环境
sqoop:
让HDFS分析关系数据库(甲骨文、MySQl、SQL Server, DB2)中的数据
管理员管理组件
生态图
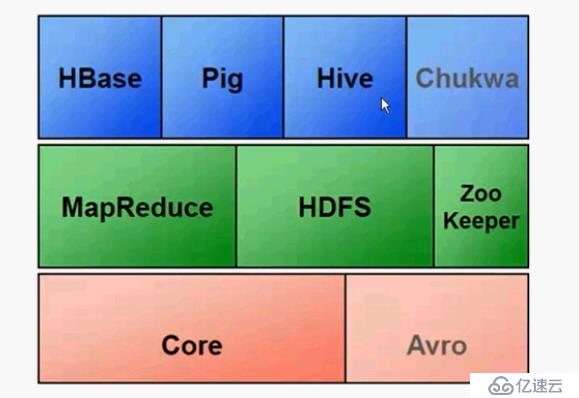
Hadoop核心组件:
MapReduce
HDFS
R语言
R是用于统计分析,绘图的语言和操作环境R是属于GNU系统的一个自由,免费,源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具
伪分布式系统基本5个进程:
JobTracker
TaskTracker
NameNode
SecondaryNameNode
DataNode
Hadoop生态各个组件之间兼容性不太好组件来自于各个开源项目
Cloudera鼎晖组合发行版是Hadoop的一个分支,比较著名的
各种配置文件. xml
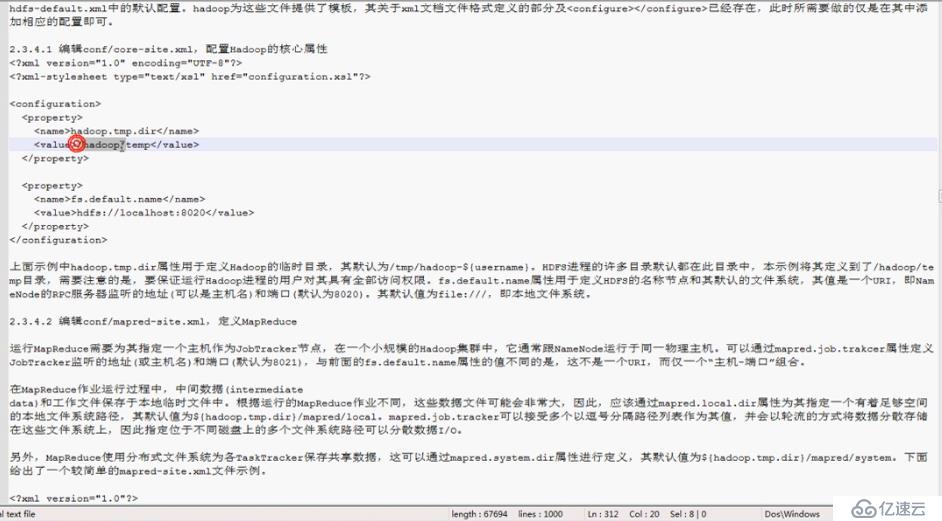
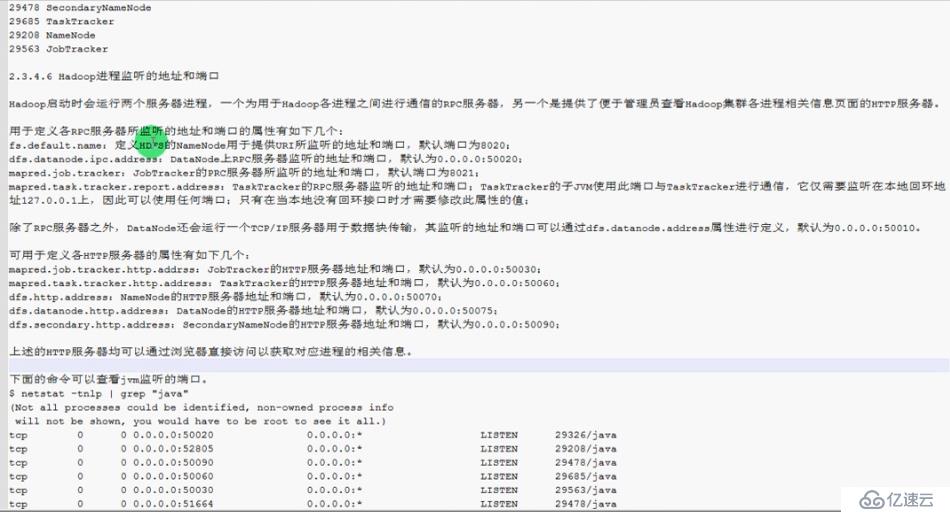
Hadoop进程监听的地址和端口