
介绍
这篇文章主要讲解了“Python中怎么使用熊猫实现数据清洗后的数据整合”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python中怎么使用熊猫实现数据清洗后的数据整合”吧!
<强>熊猫合并数据
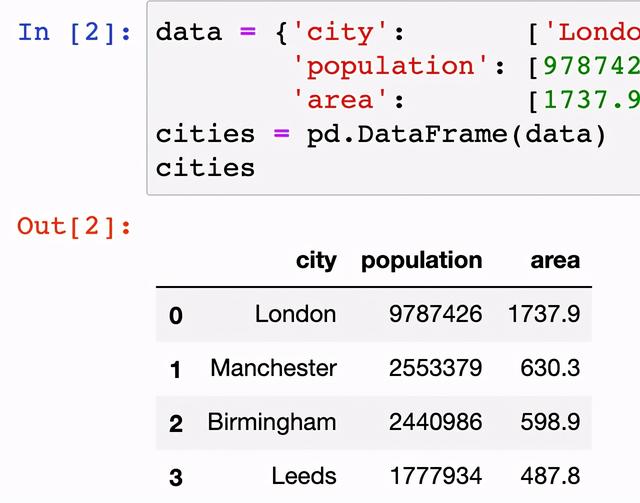
组合或合并数据时,大熊猫有几个不同选项。在Jupyter的笔记本中,创建两个新的数据帧并合并数据。可以使用append()来合并这些数据帧。【案例】将城市名,人口和面积的两组数据合并。
import pandas as pd
data =,{& # 39;城市# 39;:[& # 39;伦敦# 39;& # 39;曼彻斯特# 39;,& # 39;伯明翰# 39;,& # 39;利兹# 39;,& # 39;格拉斯哥# 39;],
,,,,,,,& # 39;人口# 39;:,(9787426,,,2553379,2440986,1777934,1209143),
,,,,,,,& # 39;区域# 39;:[,630.3,598.9,487.8 1737.9,,368.5,)}
时间=cities pd.DataFrame(数据)
data2 =,{& # 39;城市# 39;:[& # 39;利物浦# 39;& # 39;南安普顿# 39;],
,,,,,,,& # 39;人口# 39;:,(864122,,855569),
,,,,,,,& # 39;区域# 39;:[199.6,,,,192.0]}
时间=cities2 pd.DataFrame (data2)
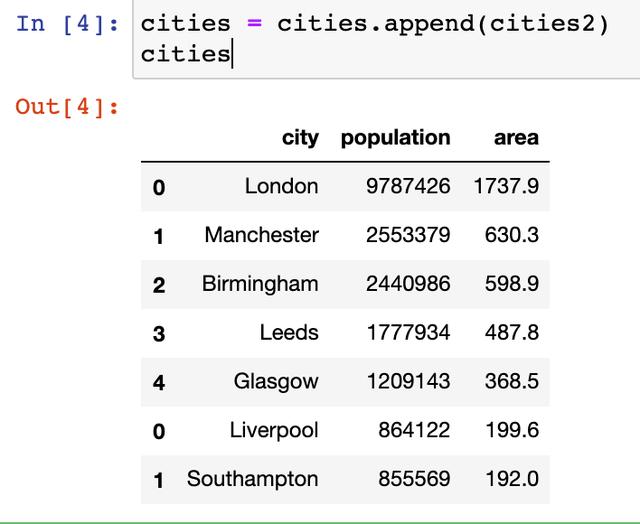
时间=cities cities.append (cities2)
城市 其操作是“data1=data1.append (data2)”将data2连接到data1的尾部。再赋值给data1。要注意data1和data2应具有相同的结构。
<强> B . . concat()
frames =,(城市,cities2] 时间=df pd.concat(帧) df
像其在ndarray上的同级函数一样numpy.concatenate (), pandas.concat()采用同类对象的列表或字典。
然后可以根据数据来源直接查看定位所需的数据。
df.loc [& # 39; y # 39;]
感谢各位的阅读,以上就是“Python中怎么使用熊猫实现数据清洗后的数据整合”的内容了,经过本文的学习后,相信大家对Python中怎么使用熊猫实现数据清洗后的数据整合这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是,小编将为大家推送更多相关知识点的文章,欢迎关注!




