
本篇文章给大家分享的是有关K 均值算法是如何让数据自动分组,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
下面要介绍的K 均值算法是一种无监督学习。
与分类算法相比,无监督学习算法又叫聚类算法,就是只有特征数据,没有目标数据,让算法自动从数据中“学习知识”,将不同类别的数据聚集到相应的类别中。
1,K 均值算法
K 均值的英文为K-Means,其含义是:
K:表示该算法可以将数据划分到K 个不同的组中。
均值:表示每个组的中心点是组内所有值的平均值。
K 均值算法可以将一个没有被分类的数据集,划分到K 个类中。某个数据应该被划分到哪个类,是通过该数据与群组中心点的相似度决定的,也就是该数据与哪个类的中心点最相似,则该数据就应该被划分到哪个类中。
关于如何计算事物之间的相似度,可以参考文章《计算机如何理解事物的相关性》。
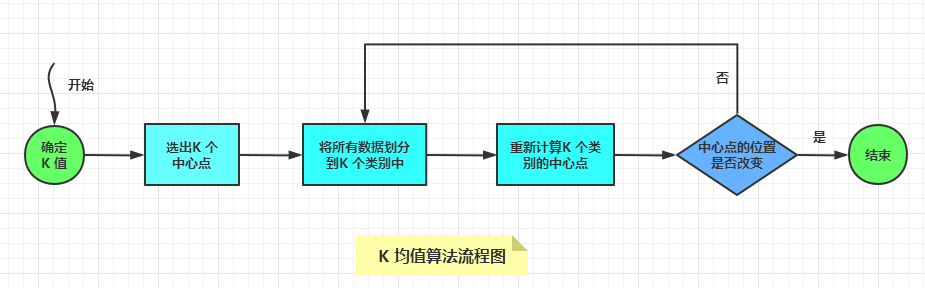
使用K 均值算法的一般步骤是:
确定K 值是多少:
对于K 值的选择,可以通过分析数据,估算数据应该分为几个类。
如果无法估计确切值,可以多试几个K 值,最终将划分效果最好的K 值作为最终选择。
选择K 个中心点:一般最开始的K 个中心点是随机选择的。
将数据集中的所有数据,通过与中心点的相似度划分到不同的类别中。
根据类别中的数据平均值,重新计算每个类别中心点的位置。
循环迭代第3,4步,直到中心点的位置几乎不再改变,分类过程就算完毕。
2,K 均值算法聚类过程
下面以一个二维数据点的聚类过程,来看下K 均值算法如何聚类。
首先,这里有一些离散的数据点,如下图:
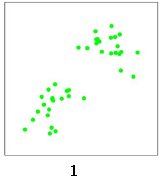
我们使用K 均值算法对这些数据点进行聚类。随机选择两个点作为两个类的中心点,分别是红色x 和蓝色x:
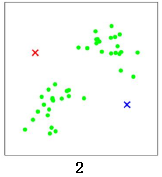
计算所有数据点到这两个中心点的距离,距离红色x 近的点标红色,距离蓝色x 近的点标蓝色:
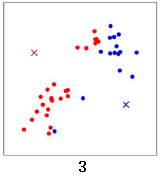
重新计算两个中心点的位置,两个中心点分别移动到新的位置:
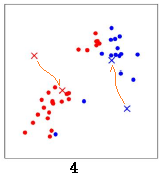
重新计算所有数据点分别到红色x 和蓝色x的距离,距离红色x 近的点标红色,距离蓝色x 近的点标蓝色:
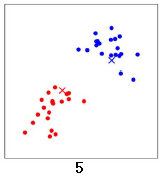
再次计算两个中心点的位置,两个中心点分别移动到新的位置:
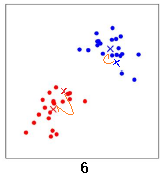
直到中心点的位置几乎不再变化,聚类结束。
以上过程就是K 均值算法的聚类过程。
3,K 均值算法的实现
K 均值算法是一个聚类算法,sklearn 库中的 cluster 模块实现了一系列的聚类算法,其中就包括K 均值算法。
来看下KMeans 类的原型:
KMeans( n_clusters=8, init=& # 39; k - means + + & # 39;,, n_init=10, max_iter=300,, 托尔=0.0001,, precompute_distances=& # 39;弃用,,, verbose=0,, random_state=没有,, copy_x=True,, n_jobs=& # 39;弃用,,, algorithm='auto')K均值算法是如何让数据自动分组




