透明抠图问题作为抠图问题的一种,其采用的方法和模型构建与通常的模型有所不同,透明抠图需要将环境光,折射率的影响纳入计算,而一般的折射光图又很难获得,因此透明抠图的模型在过去一直难以建立,或者说很难达到令人满意的效果,达摩院视觉算法团队通过双分支解码器(对象面具获取,不透明度预测),颜色纠正模块,对图像实现高精度透明抠图。
透明抠图vs非透明抠图
物体的抠图问题可以定义为求解以下的公式,即给定图像我,求解前景颜色F,背景颜色B和α哑光的线性组合:
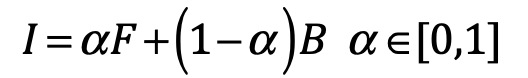
对于透明物体而言,它展现在观察者眼中的颜色是由其前景颜色,背景颜色以及环境光线经过前景物体自我反射折射混合而成的,因此,它的公式会更加复杂一些:
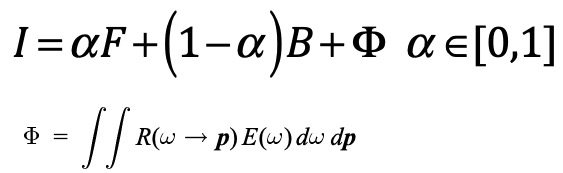
Φ表示的是环境光的影响它是所有光线E (w)与反射率方程R乘积在所有点上的二重积分,求解很复杂[28],导致实现精确的透明抠图是一个非常困难的问题,因此,现有透明抠图研究的目标也是实现视觉感受“真”实的抠图而已,并非追求完全真实的抠图结果。
现有研究
SOTA的席子算法在同时提供原图和对应trimap的情况下,可以的实现对半透物体的处理(如下图为GCA-Matting的效果),但tripmap在实际的图像的处理中难以获取,限制了这类算法其在业务中的使用。
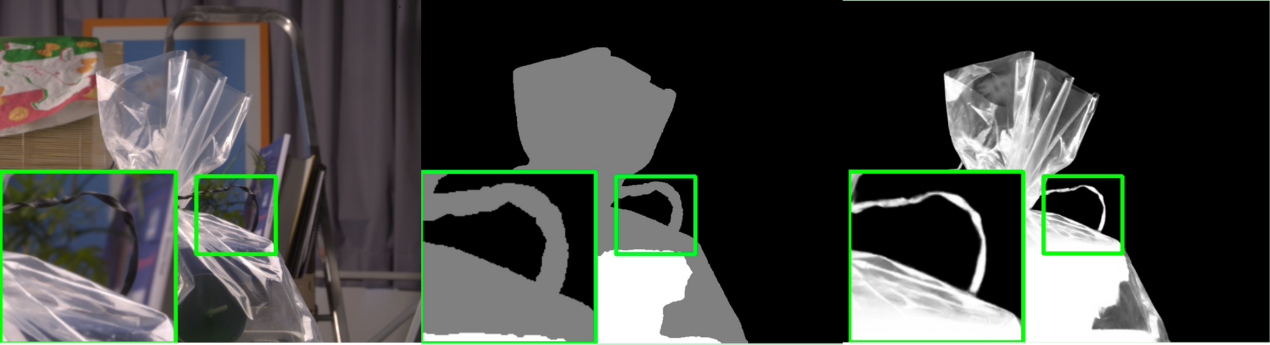
TOM-Net将透明抠图问题视为折射流的估计问题,网络支持对单图输入,经过三分支的编解码器网络,分别预测图像的对象面具,attenuative面具,面具流(折射流图),并可以通过折射流信息进一步在新的背景进行合成。该方法的局限性在于其假设物体必须全部为无色透明物体,并且在训练过程中需要折射流图作为标签,而折射流图在真实世界是非常难以获取的,因此该方法的训练数只能依赖于图形学合成,与真实透明图像的分布无法一致(图像的语义合理性存疑,例如玻璃杯在山前悬浮)。经过我们在实际数据上的测试,该方法在实际图像的表现并不理想。

分段透明物体在野外提出了基于语义分支和边缘分支结构的真实世界透明物体分割网络,通过边界注意力模块(边界注意力Modeule)增强对透明物体的分割精度,并发布了目前数量最大的透明物体分割标注数据集Trans10K。然而,文章提出的算法和发布的数据集都是处理到语义分割层面,并没有对物体的透明度做进一步处理。

问题简化
考虑到透明抠图问题本身难以求解,而且数据构建也非常困难,在实际的应用场景中,为保证同时保证算法的泛化能力和抠图效果,我们对问题进行了简化,我们假设所需处理的物体的透明部分是无色的,且所在环境的背景颜色分布相对均匀。在这样的条件下,背景的自发光或反射光的颜色可以认为是全局一致的颜色,不会出现多种颜色叠加的情况,Φ的估计就只是和背景颜色相关了。特别的,如果预知背景的颜色,可以通过将其作为先验引入Φ中,对结果进行背景杂色的抑制及去除。
模型设计
我们的模型输入为单张图像,通过编码器网络提取其深层特征。解码器设计为两个分支,分支一的解码器采用在非透明物体抠图的解码器权重,该分支注重语义级别的分割和提取,力求完整准确地获得物体所在图像区域,即对象面具。
分支二则注重对图像物体不透明度(不透明)的预测,在背景均匀的假设下,该分支预测图像各像素与背景的相似性,相似度高则说明介质的透明度高(如空气,玻璃)。而分支二由于在训练的时候没有进行语义的约束,容易存在非主体区域的噪声影响,因此,将两者进行融合可以将透明信息约束在主体范围内。融合模块的实现,可以将不透明度和ObjectMask进行图像级的像素融合,也可以将两者进行深度维度拼接,通过进一步的网络进行预测。