一、摘要
随着互联网的高速发展,数据量爆发式增长的同时,数据的存储形式也开始呈现出多样性,有结构化存储,如Mysql, Oracle等状态"置疑",半结构化甚至非结构化存储,如HBase, OSS等。那么从事数据分析的人员就面临着从多种多样的数据存储形式中提取数据而后进行多维分析,这将是一件非常具有挑战的事情。而快速BI作为新一代智能BI服务平台,恰好解决了这一难题,不仅支持多种结构化数据源的多维分析,也支持本地文件上传后的查询分析,同时还支持部分非结构化数据源的OLAP分析,甚至支持混合异构数据源的关联分析。
快速BI目前支持的数据源既可以来自阿里云数据库,也可以来自自建数据库,如下所示:



二、结构化数据源多维分析
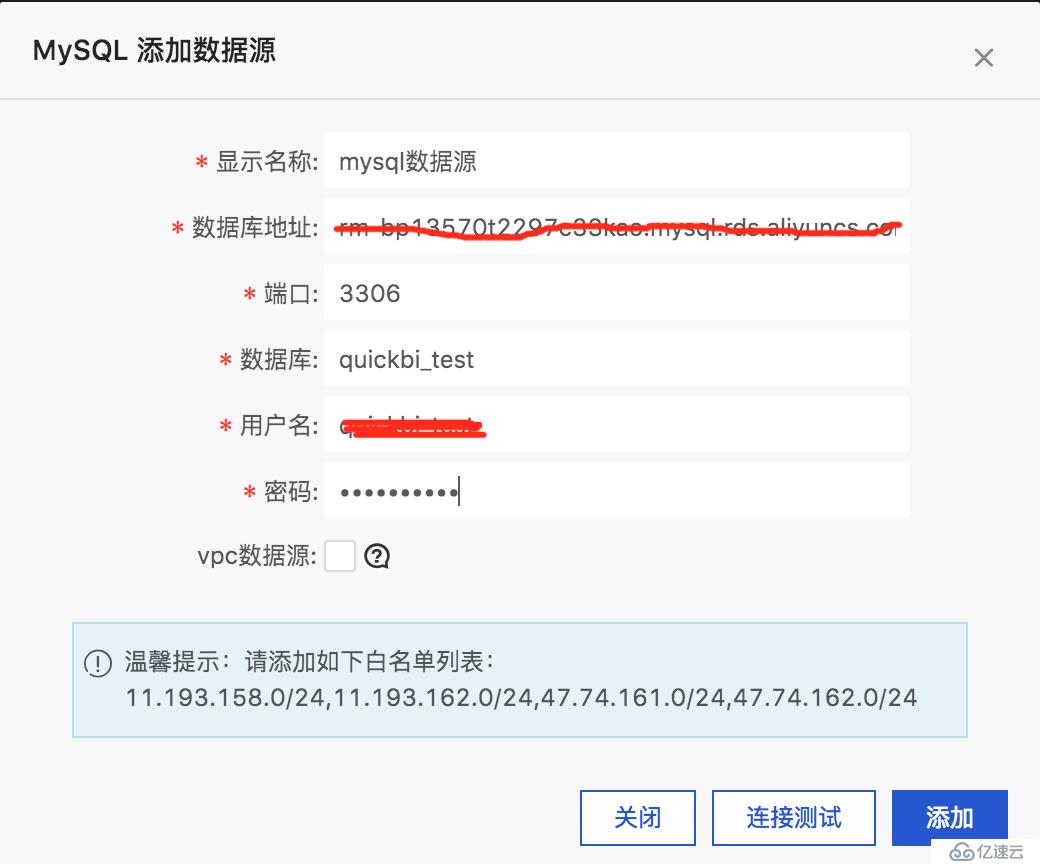
对于一般的数据源,用户在做多维分析之前需要先在快速BI数据源界面添加自己的数据源,比如MySQL数据源,如下:
数据源添加完成后,可以选择一张或多张要进行分析的数据表创建一个数据集,如下:

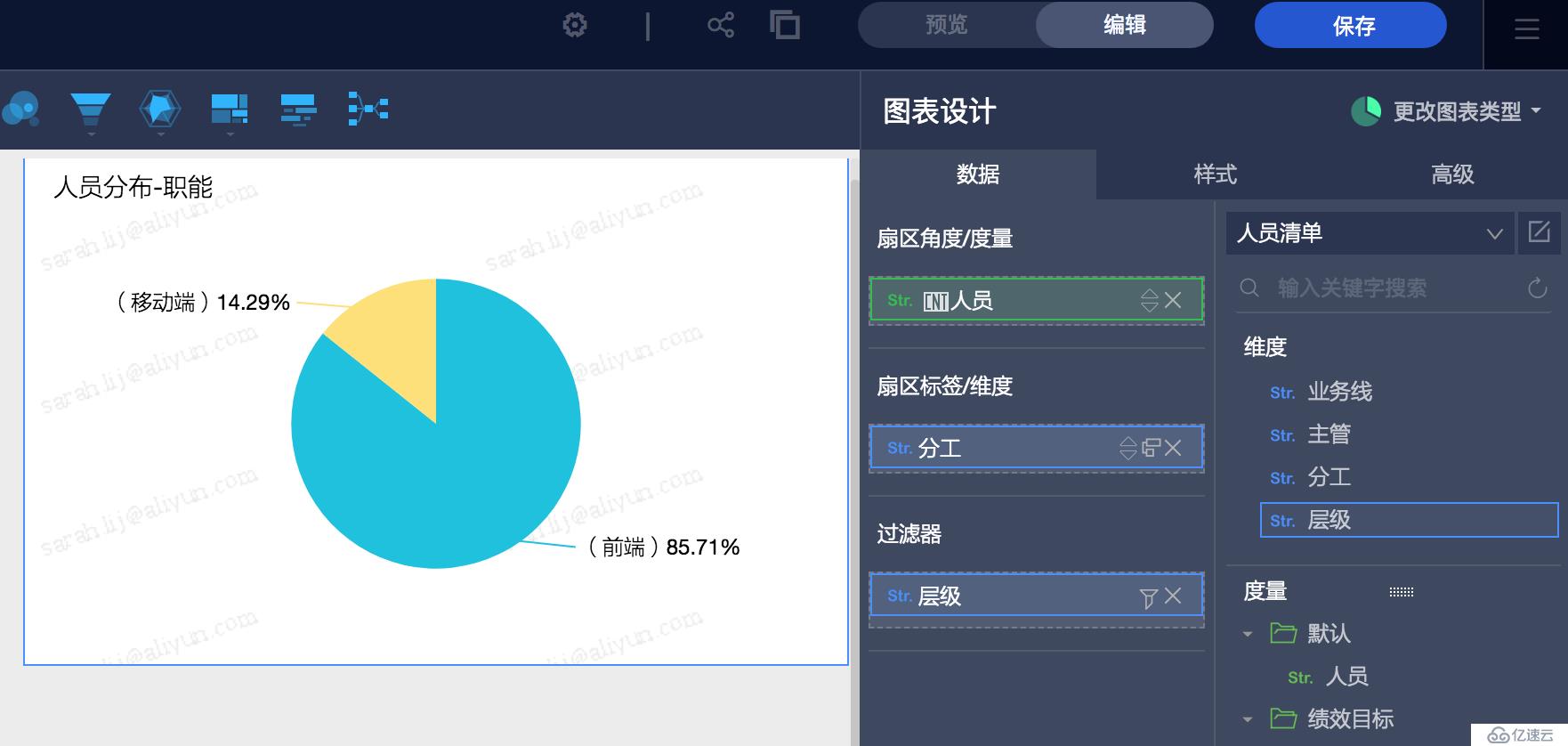
数据集创建完成后用户就可以在仪表板里拖拽维度和度量进行多维分析了,比如:
结构化数据源的多维分析相对比较简单,大致过程就是针对每次多维分析查询,根据用户选择的维度,度量及过滤条件等查询因子,生成相应结构化数据源的方言SQL,然后通过执行机下发到用户自己的数据库去执行该SQL,最后快速BI接收返回的查询结果进行可视化展现。下图展示了多维分析的流程图:

顺便介绍一下,本地文件上传支持csv和Excel两种文件类型。上传后的文件会落地到快速BI提供的一种官方数据源:探索空间。探索空间底层依赖了一种阿里云自研的MPP SQL引擎,提供存储+计算服务。
接下来的篇幅将着重介绍非结构化查询分析及混合异构数据源关联分析的原理。
三、非结构化数据源查询分析
3.1背景
近年来部分大型企业更倾向于采用诸如半结构化存储(HBase),对象存储(OSS)等能容纳较大数据规模的数据库。如何有效地帮助企业对此类数据源进行多维数据分析是目前业界BI产品的一项挑战。
在开源的数据库产品当中,存在着一些潜在的解决方案,例如,针对HDFS数据的查询,蜂巢设计了metastore组件,专门用于存储元数据,解决了从结构化查询到非结构化数据之间的映射关系,用户通过使用创建外部表的SQL的语法,可以更灵活地自定义映射的方式。另外,Apache凤凰也采取了类似的方式让用户能够使用SQL语句对HBase中的数据进行查询。经过充分调研后,针对快速BI产品自身的业务场景,结合开源计算引擎二次开发了一套用于非结构化查询的分析引擎。
3.2技术原理
对非结构化数据源进行OLAP查询,其关键在于支持SQL语法形式的数据查询.Quick BI在OLAP引擎内部采用创建外部表的SQL语法,给用户提供了一种自定义的,从非结构化数据到结构化存储的映射方式。对于诸如MySQL, Oracle等结构化的数据源而言,无须额外的元数据信息,而对于非结构化的数据源,需要提供额外的元数据信息.Metastore维护了所有非结构化数据源的元数据信息,元数据信息中反映了非结构化数据到结构化之间的映射方式.Metadb中包含了3张表,用于定义可以被SQL查询所需要的元数据信息,如下图所示:
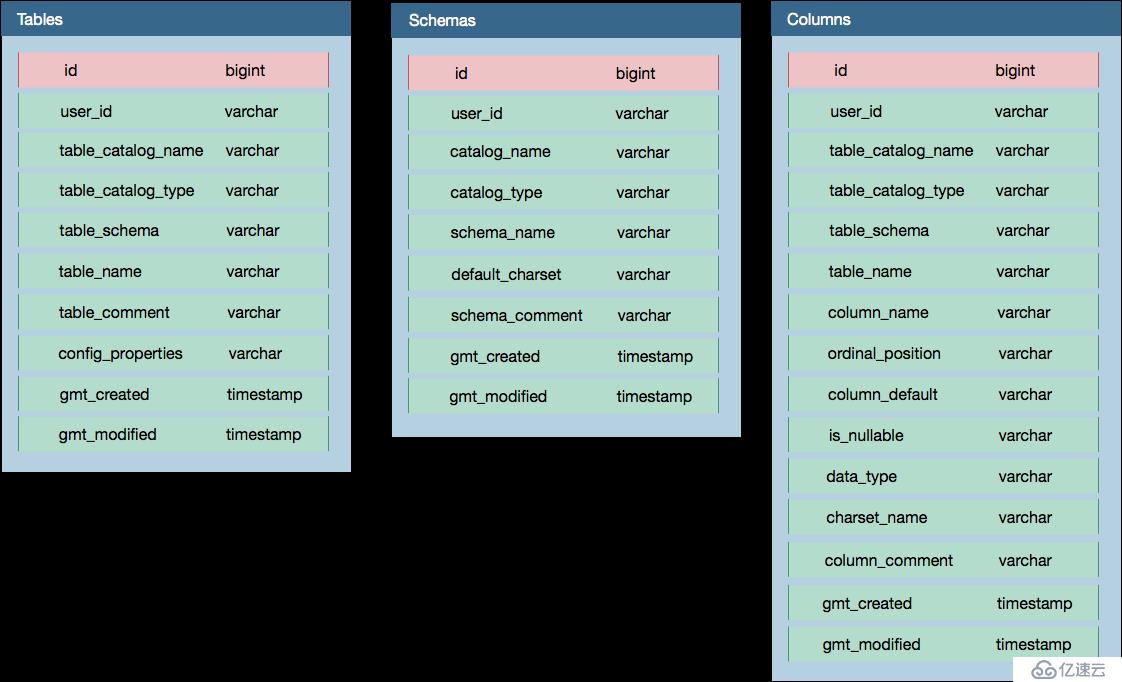
实施方案、表和列分别定义了外部表的结构,通过SQL创建外部表时,在其中加入相应的记录。查询非结构化数据源时,再读取相应的记录,对数据进行解析。