官网http://hadoop.apache.org/
hadoop三大组件
HDFS:分布式存储系统https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
MapReduce:分布式计算系统http://hadoop.apache.org/docs/r2.8.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
纱:hadoop的资源调度系统http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html
回想起以前做过一个中铁轨道激光测量轨道平整的项目,一段50公里的数据库大小是400克,光是找空间复制出来就是头大,现在有了分布式的数据库和计算平台就可以非常方便的进行。


Mapper
映射器将输入键/值对映射到一组中间键/值对中。
- <李>映射是将输入记录转换为中间记录的单个任务。转换后的中间记录不需要与输入记录相同的类型。给定的输入对可以映射到零或多个输出对。
<李> Hadoop MapReduce的框架产生一个地图的任务由每个InputSplit工作InputFormat生成。
李李 <>总的来说,制图的实现是通过工作传递到工作setmapperclass(类)的方法。框架调用图(writablecomparable写,上下文)每个键/值对,任务在InputSplit对。然后应用程序可以覆盖清除(上下文)方法来执行任何必需的清理工作。
李李 <>输出对不需要与输入对相同的类型。给定的输入对可以映射到零或多个输出对。输出对被调用的上下文所写(writablecomparable,可写)。
应用程序可以使用计数器报告其统计数据。
- <李>所有与给定输出键相关联的中间值随后由框架分组,并传递给减速器以确定最终输出。用户可以通过指定一个比较器通过工作控制分组.setgroupingcomparatorclass(类)。
<李> 对映射器输出进行排序,然后对每个减速器进行分区。分区的总数与任务的减少任务数相同。用户可以控制键(因此记录)通过实现一个自定义的分割器去哪。
<李> 用户可以选择指定一个合成器,通过工作.setcombinerclass(类),执行中间输出的地方聚集,这有助于减少从制图到减速器的数据量。
李李 <>中间排序的输出总是存储在一个简单(键,键值,值)格式中。应用程序可以控制的话,又如何,中间输出被压缩和compressioncodec可以通过配置。
减速器
- <李>减速减少一组中间值份额较小的一组值的关键。
<李> 数量减少了工作组通过工作的用户.setnumreducetasks (int)。
李李 <>总的来说,减速器的实现是通过岗位工作经工作.setreducerclass(类)方法,可以重写它初始化自己。框架调用减少(writablecomparable个& lt;写祝辞,& lt;上下文)为每个关键方法(值列表)在在分组的输入对。应用程序可以重写清理(上下文)执行任何所需的清理方法。
李李 <>减速器有3个主要阶段:洗牌,排序和减少。
洗牌洗牌
- <李>输入减速器的排序输出的映射。在这一阶段的框架带来的所有映射器输出相应的分区,通过HTTP。
瓜分者分区
- <李>分区空间分区是关键。
李李 <>分区分配的关键的中间图的输出。”密钥或密钥的子集的冰中)使用的分区,通常是一个市的哈希函数。的总数分区冰茶一样的号码减少任务的工作,这因此米江森自控的减少任务的中间密钥和因此记录)的冰后期两个还原。
李李 <> hashpartitioner是默认的分区。
计数器计数器
- <李>计数器是MapReduce应用程序报告其统计数据的工具。
<李> 映射器和减速器实现可以使用计数器报告统计数据。
- Hadoop的MapReduce的附带了一个普遍有用的映射器,减速器库,并计划。
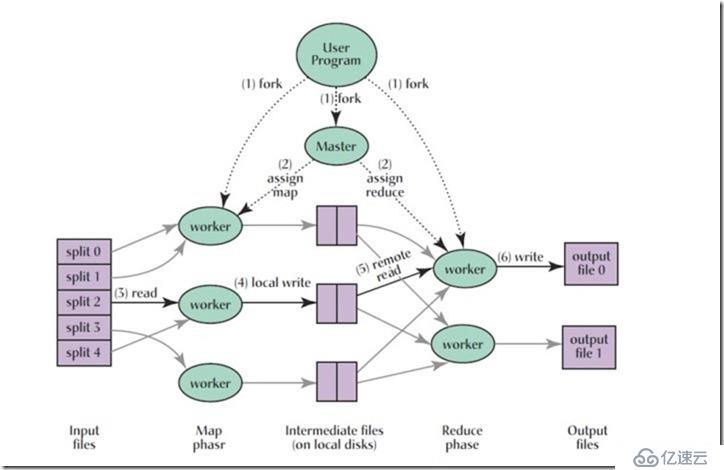
其实MapReduce讲的就是分而治之的程序处理理念,把一个复杂的任务划分为若干个简单的任务分别来做。另外,就是程序的调度问题,哪些任务给哪些Mapper来处理是一个着重考虑的问题。MapReduce的根本原则是信息处理的本地化,哪台PC持有相应要处理的数据,哪台PC就负责处理该部分的数据,这样做的意义在于可以减少网络通讯负担。最后补上一副经典的图来做最后的补充,毕竟,图表往往比文字更有说服力。