Hadoop是什么h5>
<李> Hadoop是一个开源的大数据框架李
<李> Hadoop是一个分布式计算的解决方案李
<李> Hadoop=HDFS(分布式文件系统)+ MapReduce(分布式计算)
Hadoop核心
<李> HDFS分布式文件系统:存储是大数据技术的基础李
<李> MapReduce编程模型:分布式计算是大数据应用的解决方案李
<编辑> Hadoop基础架构
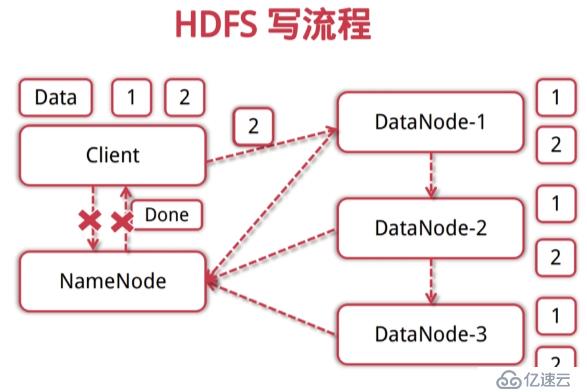
HDFS概念
数据块
NameNode
DataNode
数据块:抽象块而非整个文件作为存储单;默认大小64 mb一般设置为128米,备份X3。
NameNode:管理文件系统的命名空间,存放文件元数据;维护着文件系统的所有文件和目录,文件与数据块的映射;记录每个文件中各个块所在数据节点的信息。
DataNode:存储并检索数据块;向NameNode更新所存储块的列表。
-
<李>适合大文件存储,支持结核病、PB级的数据存储,并有副本策略。
<李>可以构建在廉价的机器上,并有一定的容错和恢复机制。
<李>支持流式数据访问,一次写入多次读取最高效。
-
<李>不适合大量小文件存储李
<李>不适合并发写入,不支持文件随机修改。
<李>不支持随机读取等低延时的访问方式。
Hadoop各个功能模块的理解
<强> 1,HDFS模块
HDFS负责大数据的存储,通过将大文件分块后进行分布式存储方式,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,HDFS是个相对独立的模块,可以为纱提供服务,也可以为HBase等其他模块提供服务。
<强> 2,线模块
纱是一个通用的资源协同和任务调度框架,是为了解决Hadoop1.x中MapReduce里NameNode负载太大和其他问题而创建的一个框架。
纱是个通用框架,不止可以运行MapReduce,还可以运行火花,风暴等其他计算框架。
<强> 3,MapReduce模块
MapReduce是一个计算框架,它给出了一种数据处理的方式,即通过地图阶段,减少阶段来分布式地流式处理数据。它只适用于大数据的离线处理,对实时性要求很高的应用不适用。
<编辑>延伸思考-
<李> <>强如何通过Hadoop存储小文件?
<强>,在客户端将小文件合并为大文件。
Hadoop会把每一个小文件传递给地图()函数,而Hadoop在调用地图()函数时会创建一个映射器,这样就会创建了大量的映射器,应用的运行效率并不高。如果使用和存储小文件,通常就会创很多的映射器。解决小文件问题的主要目的就是通过合并小文件为更大的文件来加快Hadoop的程序的执行,解决小文件问题可以减少映射()函数的执行次数,相应地提高Hadoop作业的整体性能。
<强> b,使用Hadoop的CombineFileInputFormat
使用Hadoop API(抽象类CombineFileInputFormat)来解决小文件的问题。抽象类CombineFileInputFormat的基本思想是通过使用一个定制的InputFormat允许将小文件合并到Hadoop的分片(分裂)或块(块)中。 <李> <>强当有节点故障的时候,集群是如何继续提供服务的,如何读,写? <李> <>强哪些是影响MapReduce性能的因素?
,硬件(或者资源)因素,如CPU、磁盘I/O,网络带宽和内存大小。
b,底层存储系统。
c,输入数据,分拣(shuffle)数据以及输出数据的大小,这与作业的运行时间紧密相关。
d,作业算法(或者程序),如地图,减少分区,和压缩结合起来。有些算法很难在MapReduce中概念化,或者在MapReduce中效率可能会降低。