一、搭建动物园管理员集群
管理员是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务,分布式同步(分布式同步),命名服务(命名服务),集群维护(集团维护)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务.ZooKeeper本身可以以单机模式安装运行,不过它的长处在于通过分布式饲养员集群(一个领袖,多个追随者),基于一定的策略来保证管理员集群的稳定性和可用性,从而实现分布式应用的可靠性。
1。在zookeeper.apache.org上下载zookeeper-3.4.8.tar.gz
2。解压焦油-xzvf zookeeper-3.4.8.tar.gz
3。修改权限sudo乔恩- r cms (ubuntu用户名)zookeeper-3.4.8
4。修改配置文件/etc/profile,增加

5。对管理员的配置文件的参数进行设置
进入zookeeper-3.4.5/conf
1) cp zoo_sample。cfg zoo.cfg
2)在动物园管理员下新建一个存放数据的目录
mkdir zookerperdata
3) vim动物园。cfg 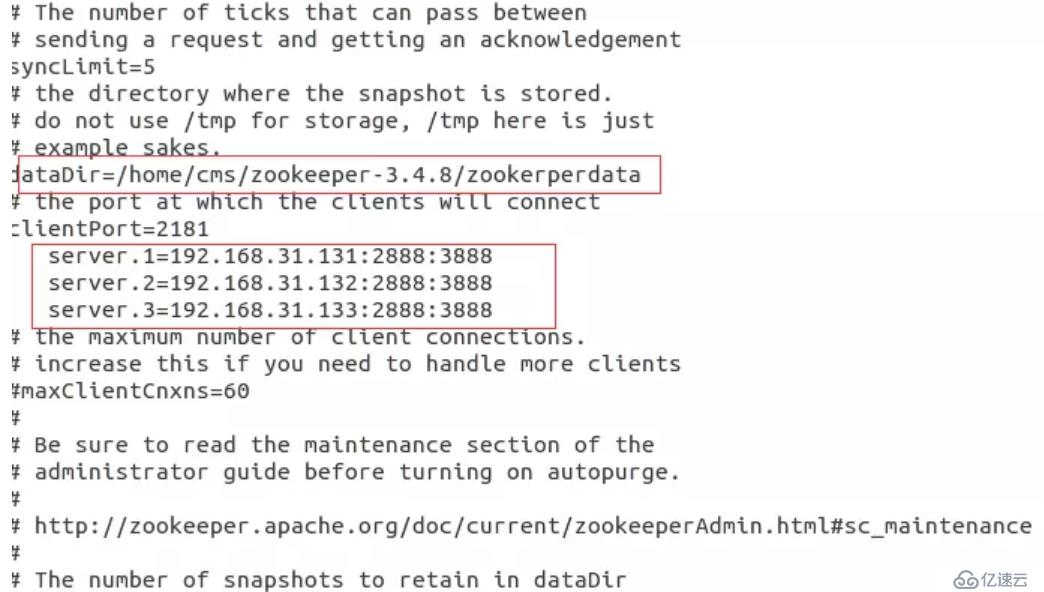
4)注意上图的配置中主人,slave1分别为主机名
在上面的配置文件中“server.id=主持人:端口:port"中的第一个端口是从机器(追随者)连接到主机器(领袖)的端口号,第二个港口是进行领导选举的端口号。
5)创建myid
接下来在dataDir所指定的目录下(zookeeper-3.4.8/zookerperdata/)创建一个文件名为myid的文件,文件中的内容只有一行,为本主机对应的id值,也就是上图中服务器。id中的id。例如:在服务器1中的myid的内容应该写入1。
vim myid
6)远程复制到slave1, slave2相同的目录下
scp - r zookeeper-3.4.8 cms@slave1:/home/cms/
scp - r zookeeper-3.4.8 cms@slave1:/home/cms/
7)修改slave1, slave2机器上的myid的值分别为2和3
启动动物园管理员集群
在动物园管理员集群的每个结点上,执行启动动物园管理员服务的脚本,如下所示:

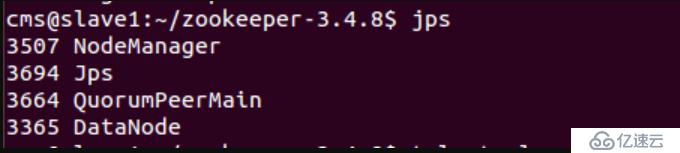

其中,QuorumPeerMain是动物园管理员进程,启动正常。
如上依次启动了所有机器上的动物园管理员之后可以通过管理员的脚本来查看启动状态,包括集群中各个结点的角色(或是领袖,或是追随者),如下所示,是在动物园管理员集群中的每个结点上查询的结果
二,搭建卡夫卡集群
1。下载
下载官网:http://kafka.apache.org/downloads
下载版本:与自己安装的Scala版本对应的版,本个人习惯是下载最新版本的前一版
kafka_2.11-0.10.0.1.tgz
2。安装
焦油-xzf kafka_2.11-0.10.0.1。tgz
cp kafka_2.11-0.10.0.1。tgz/home/cms/kafka
3。配置环境变量
即路径,路径,意义不大,可不配置
4。修改配置文件卡夫卡/config/服务器。属性
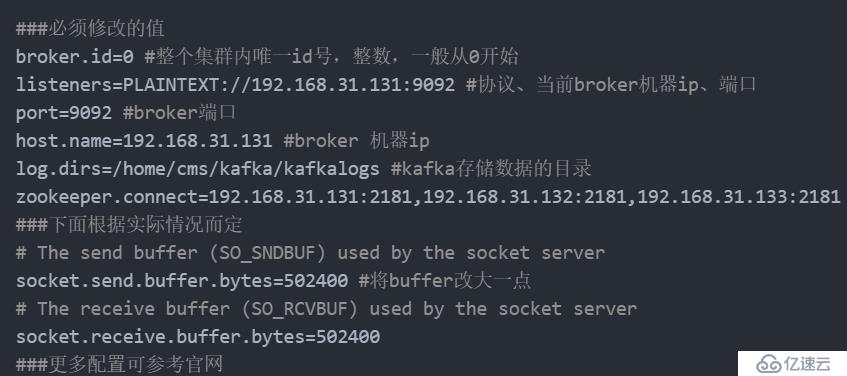
5。在卡夫卡的目录下,建立卡夫卡存储数据的目录
mkdir kafkalogs
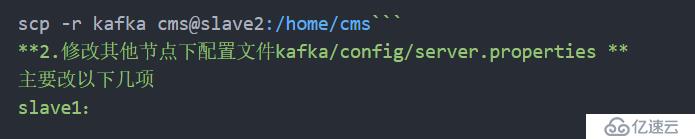
6。其他节点配置
将卡夫卡文件复制到其他节点
代理。id=1 #整个集群内唯一id号,整数,一般从0开始
听众=明文://192.168.31.132:9092 #协议,当前代理机器ip、端口
=9092 #港代理端口
host.name=192.168.31.132 #代理机器ip
7。每个节点下启动zookerper
8。启动卡夫卡进程,在每个节点的卡夫卡/bin目录下
——管理员:饲养员集群列表,用英文逗号分隔。可以不用指定饲养员整个集群内的节点列的表,只指定某个或某几个动物园管理员节点列表也是你可以的
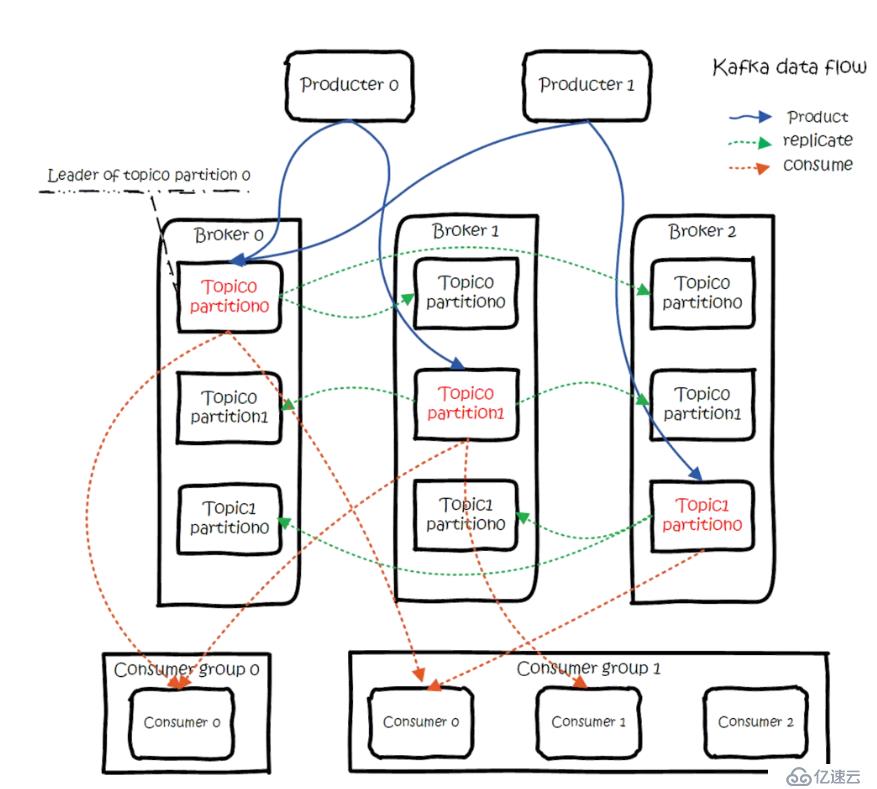
复制因子:复制数目,提供故障转移机制,1代表只在一个代理上有数据记录,一般值都大于1,代表一份数据会自动同步到其他的多个经纪人,防止某个经纪人宕机后数据丢失。
分区:一个主题可以被切分成多个分区,一个消费者可以消费多个分区,但一个分区只能被一个消费者消费,所以增加分区可以增加消费者的吞吐量.kafka只保证一个分区内的消息是有序的,多个一个分区之间的数据是无序的。