德鲁伊的单机版安装参考:https://blog.51cto.com/10120275/2429912
德鲁伊实时接入卡夫卡的过程
下载,安装,启动卡夫卡过程:
<代码> wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.1/kafka_2.11-2.2.1.tgz 焦油-zxvf kafka_2.11-2.2.1.tgz ln - s kafka_2.11-2.2.1卡夫卡 KAFKA_HOME/kafka-server-start美元。sh卡夫卡~//config/服务器。属性1在/dev/null 2祝辞,1,
创建主题:维基百科
<代码>/bin/kafka-topics。sh——创建管理员localhost: 2181 - replication因子设置分区1——1——主题维基百科
解压wikiticker sampled.json——2015 - 09 - 12。广州文件,这个步骤是给卡夫卡主题准备输入文件
<代码> cd DRUID_HOME美元/快速入门教程 gunzip - k wikiticker - 2015 - 09 - 12 - sampled.json.gz
这个步骤操作完成后,在美元DRUID_HOME/快速入门教程文件夹下生成wikiticker - 2015 - 09 - 12 - sampled.json
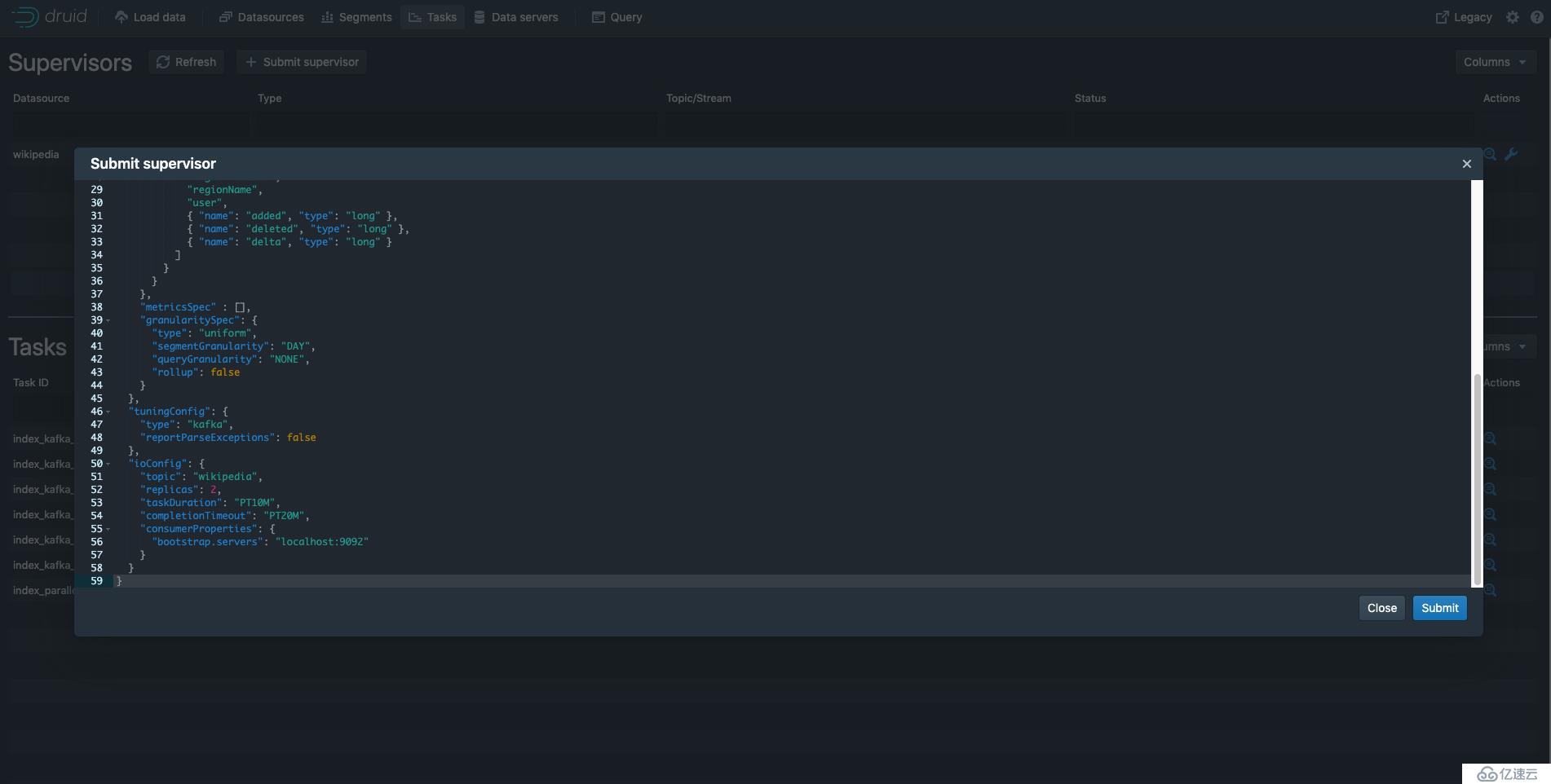
上图配置文件如下,其中bootstrap.servers配置卡夫卡地址
<代码> {
“类型”:“卡夫卡”,
" dataSchema ": {
“数据源”:“维基百科”,
“解析”:{
“类型”:“字符串”,
" parseSpec ": {
“格式”:“json”,
" timestampSpec ": {
“列”:“时间”,
“格式”:“自动”
},
" dimensionsSpec ": {
“维度”:[
“通道”,
“某个”,
“评论”,
“countryIsoCode”,
“countryName”,
“isAnonymous”,
“isMinor”,
“isNew”,
“isRobot”,
“isUnpatrolled”,
“metroCode”,
“名称”,
“页面”,
“regionIsoCode”,
“regionName”,
“用户”,
{" name ":“添加”,“类型”:“长”},
{" name ":“删除”,“类型”:“长”},
{" name ":“δ”、“类型”:“长”}
]
}
}
},
“metricsSpec”: [],
" granularitySpec ": {
“类型”:“制服”,
“segmentGranularity”:“天”,
“queryGranularity”:“没有”,
“汇总”:假的
}
},
" tuningConfig ": {
“类型”:“卡夫卡”,
“reportParseExceptions”:假的
},
" ioConfig ": {
“主题”:“维基百科”,
“副本”:2
:“taskDuration PT10M”,
:“completionTimeout PT20M”,
" consumerProperties ": {
“引导。服务器”:“localhost: 9092”
}
}
}
接下来要将wikiticker - 2015 - 09 - 12 - sampled.json文件内容,利用卡夫卡生产者脚本写入维基百科的话题中
<代码>出口KAFKA_OPTS=" -Dfile.encoding=utf - 8”/bin/kafka-console-producer。sh——券商名单上localhost: 9092——主题维基百科& lt;{PATH_TO_DRUID}/快速入门教程/wikiticker - 2015 - 09 - 12 sampled.json