本期内容:
,,1、数据接收架构设计模式
,,2、数据接收源码彻底研究
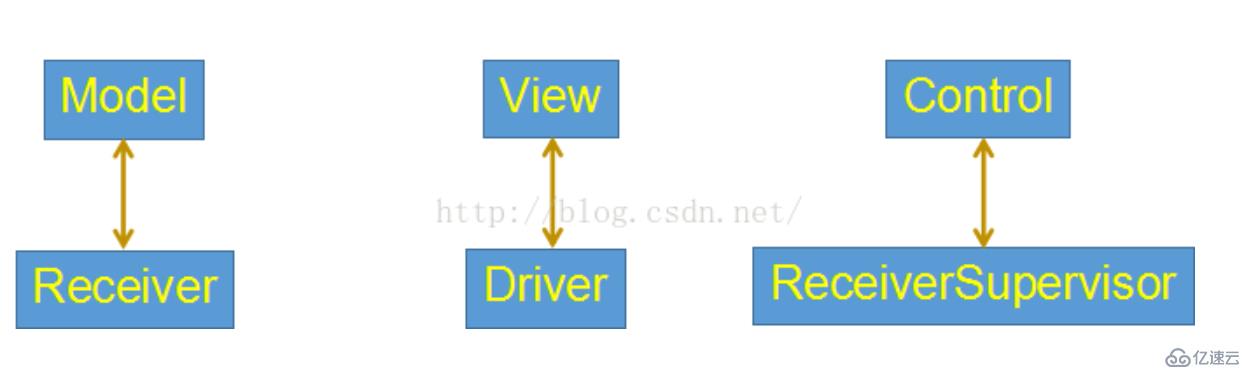
1,接收器接受数据的过程类似于MVC模式:
接收机,ReceiverSupervisor和司机的关系相当于模型,控制,看来,也就是MVC。
模型就是接收器,存储数据控制,就是ReceiverSupervisor,司机是获得元数据,也就是视图。
2,数据的位置信息会被封装到抽样里面。
3,接收器接受数据,交给ReceiverSupervisor去存储数据。
4, ReceiverTracker是通过发送一个又一个的工作,每个工作只有一个任务,每个任务里面就只有一个ReceiverSupervisor,用这个函数启动每一个接收器。
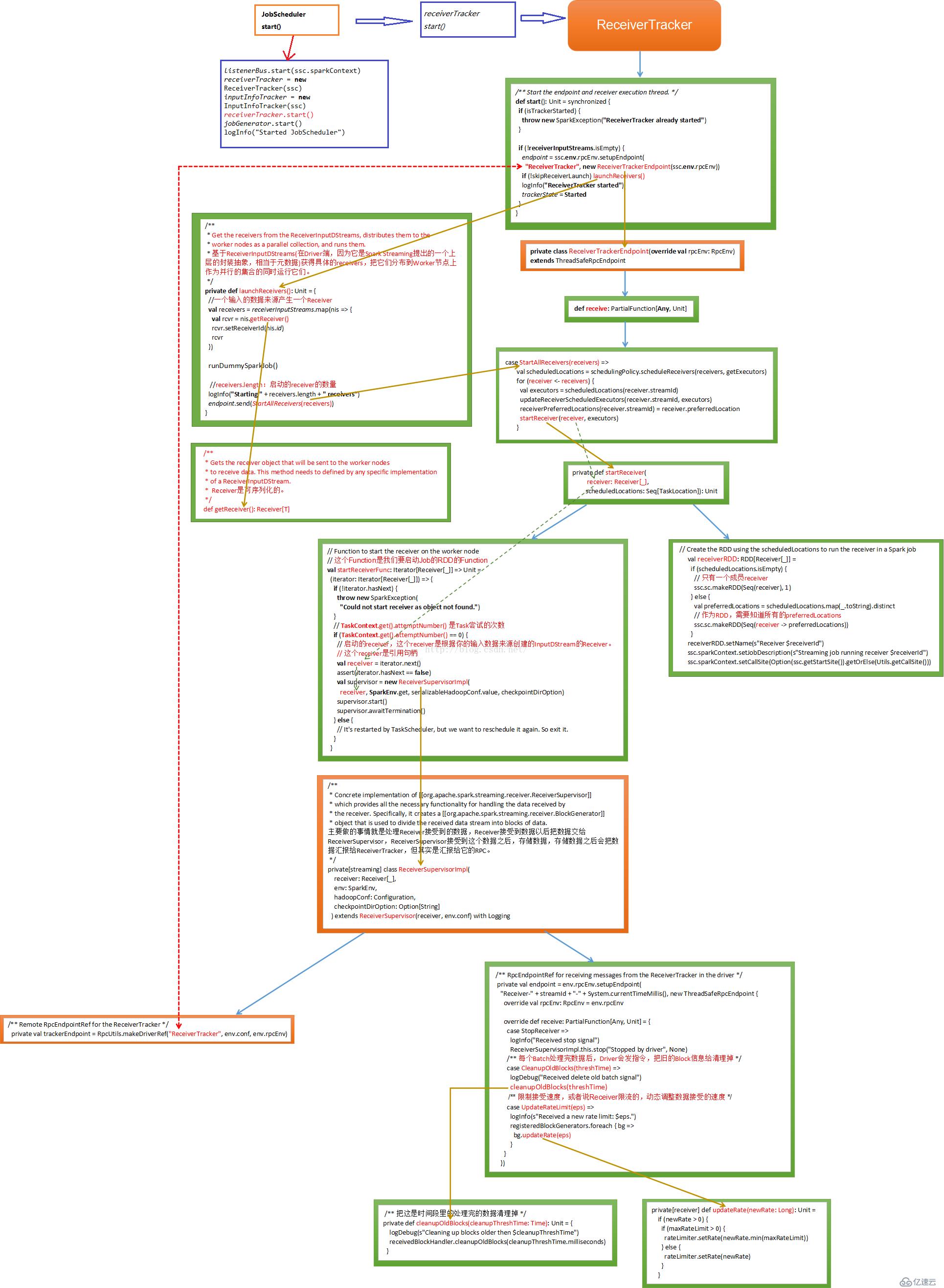
下面我们简单的看下接收机启动流程,应用程序首先通过JobScheduler开始的方法来启动ReceiverTracker开始的方法:
def 开始():,Unit =, synchronized {
if (eventLoop !=, null), return //, scheduler has already been 开始
logDebug (“Starting JobScheduler")
时间=eventLoop new EventLoop [JobSchedulerEvent] (“JobScheduler"), {
override protected def onReceive(事件:JobSchedulerEvent):, Unit =, processEvent(事件)
override protected def onError (e: Throwable):, Unit =, reportError (“Error job 拷贝;scheduler",, e)
,,}
eventLoop.start ()//,attach rate controllers of input streams 用receive batch completion 更新
for {
,,,inputDStream & lt;作用;ssc.graph.getInputStreams
,,,rateController & lt;作用;inputDStream.rateController
},ssc.addStreamingListener (rateController)
listenerBus.start (ssc.sparkContext)
时间=receiverTracker new ReceiverTracker (ssc)
时间=inputInfoTracker new InputInfoTracker (ssc)
receiverTracker.start(),//接收器启动
jobGenerator.start ()
logInfo才能(“Started JobScheduler")
} 通过调用receiverTracker.start()方法来进行一系列的操作:
/* *, Start 从而endpoint 以及receiver execution 线程只*/开始():def Unit =, synchronized {
if (isTrackerStarted), {
throw new SparkException (“ReceiverTracker already started")
,,}
if (! receiverInputStreams.isEmpty), {
时间=endpoint ssc.env.rpcEnv.setupEndpoint (
“ReceiverTracker",, new ReceiverTrackerEndpoint (ssc.env.rpcEnv)),//Rpc消息通信,获取接收机的状态
if (! skipReceiverLaunch), launchReceivers(),//启动接收器
,,,logInfo (“ReceiverTracker started")
trackerState =开始
}
} 下面通过画图简单的描述下接收机启动的内部机制:
参考博客:http://blog.csdn.net/hanburgud/article/details/51471047
,,,,,,,,,,,,,,,,, http://lqding.blog.51cto.com/9123978/1774426