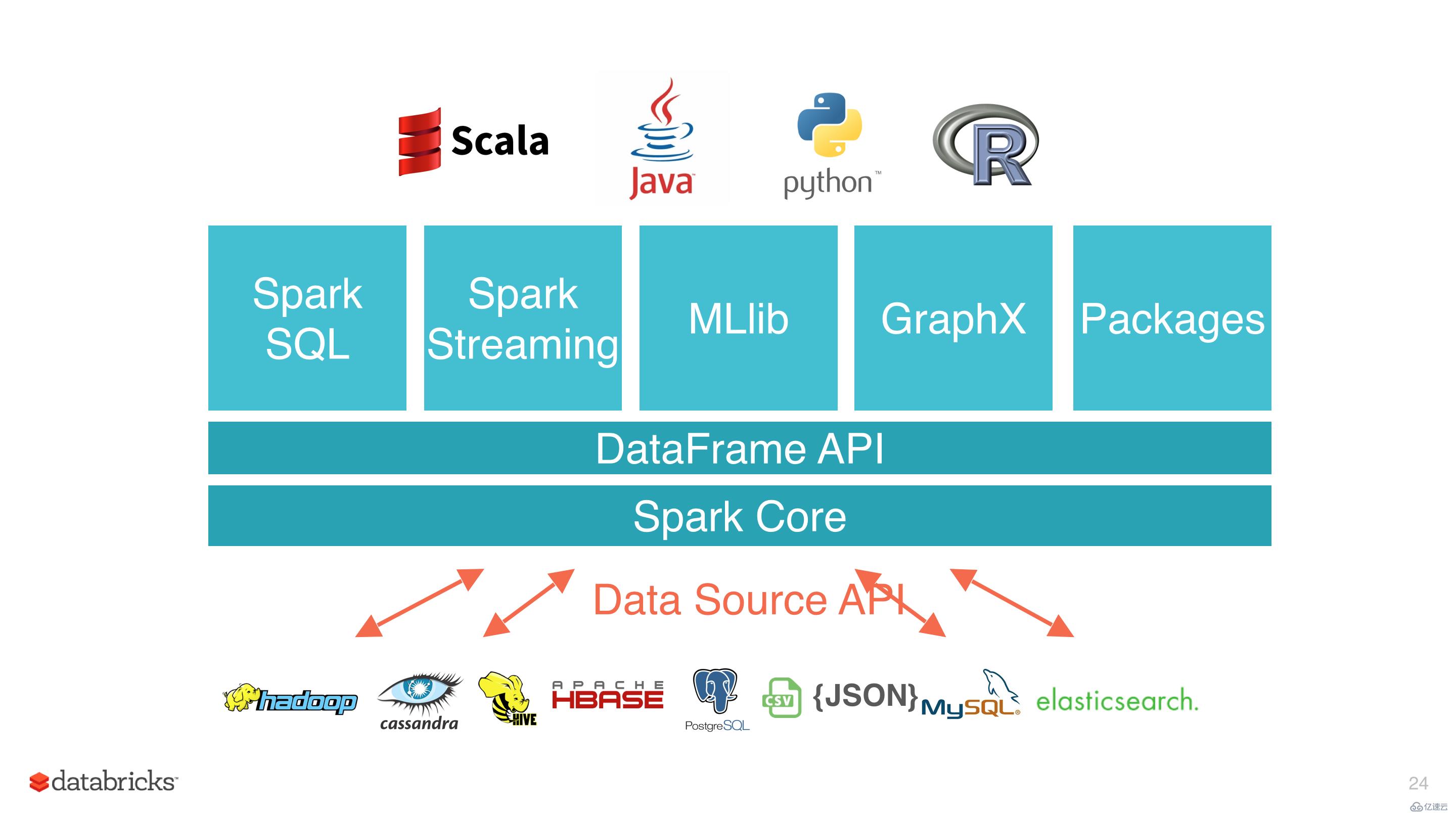
一、简介
火花于2009年诞生于加州大学伯克利分校AMPLab, 2013年被捐赠给Apache软件基金会,2014年2月成为Apache的顶级项目。相对于MapReduce的批处理计算,火花可以带来上百倍的性能提升,因此它成为继MapReduce之后,最为广泛使用的分布式计算框架。
二、特点
Apache火花具有以下特点:
-
<李>使用先进的DAG调度程序,查询优化器和物理执行引擎,以实现性能上的保证;李
<李>多语言支持,目前支持的有Java, Scala, Python和R;李
<李>提供了80多个高级API,可以轻松地构建应用程序,李
<李>支持批处理,流处理和复杂的业务分析,李
<李>丰富的类库支持:包括SQL, MLlib, GraphX和火花流等库,并且可以将它们无缝地进行组合,李
<李>丰富的部署模式:支持本地模式和自带的集群模式,也支持在Hadoop,便,Kubernetes上运行,李
<李>多数据源支持:支持访问HDFS, Alluxio,卡桑德拉,HBase,蜂巢以及数百个其他数据源中的数据。
三,集群架构
术语(术语) 意义(含义) 应用程序 火花应用程序,由集群上的一个司机节点和多个执行人节点组成。 驱动程序 主运用程序,该进程运行应用的主要()方法并且创建SparkContext 集群管理器 集群资源管理器(例如,Standlone经理,便,纱) 工作者节点 执行计算任务的工作节点 遗嘱执行人 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 任务 被发送到执行者中的工作单元 
3.1火花SQL
火花SQL主要用于结构化数据的处理。其具有以下特点:
-
<李>能够将SQL查询与火花程序无缝混合,允许您使用SQL或DataFrame API对结构化数据进行查询;李
<李>支持多种数据源,包括蜂巢,Avro,拼花,兽人,JSON和JDBC,李
<李>支持HiveQL语法以及用户自定义函数(UDF),允许你访问现有的蜂巢仓库;李
<李>支持标准的JDBC和ODBC连接;李
<李>支持优化器,列式存储和代码生成等特性,以提高查询效率。
3.2火花流
火花流主要用于快速构建可扩展,高吞吐量,高容错的流处理程序。支持从HDFS,水槽,卡夫卡,Twitter和ZeroMQ读取数据,并进行处理。

火花流的本质是微批处理,它将数据流进行极小粒度的拆,分拆分为多个批处理,从而达到接近于流处理的效果。
3.3 MLlib
MLlib是火花的机器学习库。其设计目标是使得机器学习变得简单且可扩展。它提供了以下工具:
-
<李> <强>常见的机器学习算法强:如分类,回归,聚类和协同过滤;李
<李> <>强特征化:特征提取,转换,降维和选择,李
<李> <>强管道:用于构建、评估和调整毫升管道的工具,李
<李> <>强持久性:保存和加载算法、模型,管道数据,李
<李> <>强实用工具:线性代数,统计,数据处理等。