<>强如果这是第二次看到我的文章, <强>欢迎强文末扫码订阅我的个人公众号(跨界架构师)哟~,,
本文长度为<强> 4229字强,建议阅读<强> 11 <强>分钟。
,
这是本系列中既“数据一致性”后的第二章节——“高可用”的完结篇。
,
前面几篇中z哥跟你聊了聊做“高可用”的意义,以及如何做“负载均衡”和“高可用三剑客”()。这次,我们来聊一聊在保证对外高可用的同时,憋出的“内伤”该如何通过“补偿”机制来自行消化。
,
,
一、“补偿”机制的意义?
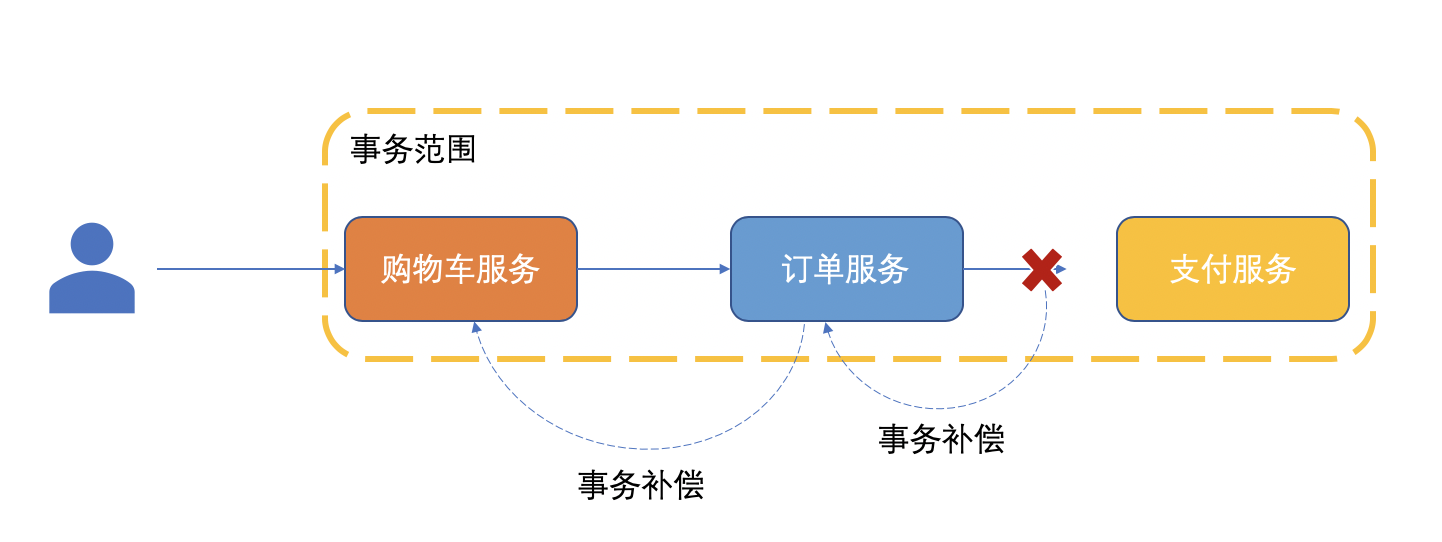
以电商的购物场景为例:
客户端——在购物车微服务——在订单微服务——比;支付微服务。
这种调用链非常普遍。
那么为什么需要考虑补偿机制呢?
正如之前几篇文章所说,一次跨机器的通信可能会经过DNS 服务,网卡、交换机、路由器、负载均衡等设备,这些设备都不一定是一直稳定的,在数据传输的整个过程中,只要任意一个环节出错,都会导致问题的产生。
而在分布式场景中,一个完整的业务又是由多次跨机器通信组成的,所以产生问题的概率成倍数增加。
但是,这些问题并不完全代表真正的系统无法处理请求,所以我们应当尽可能的自动消化掉这些异常。
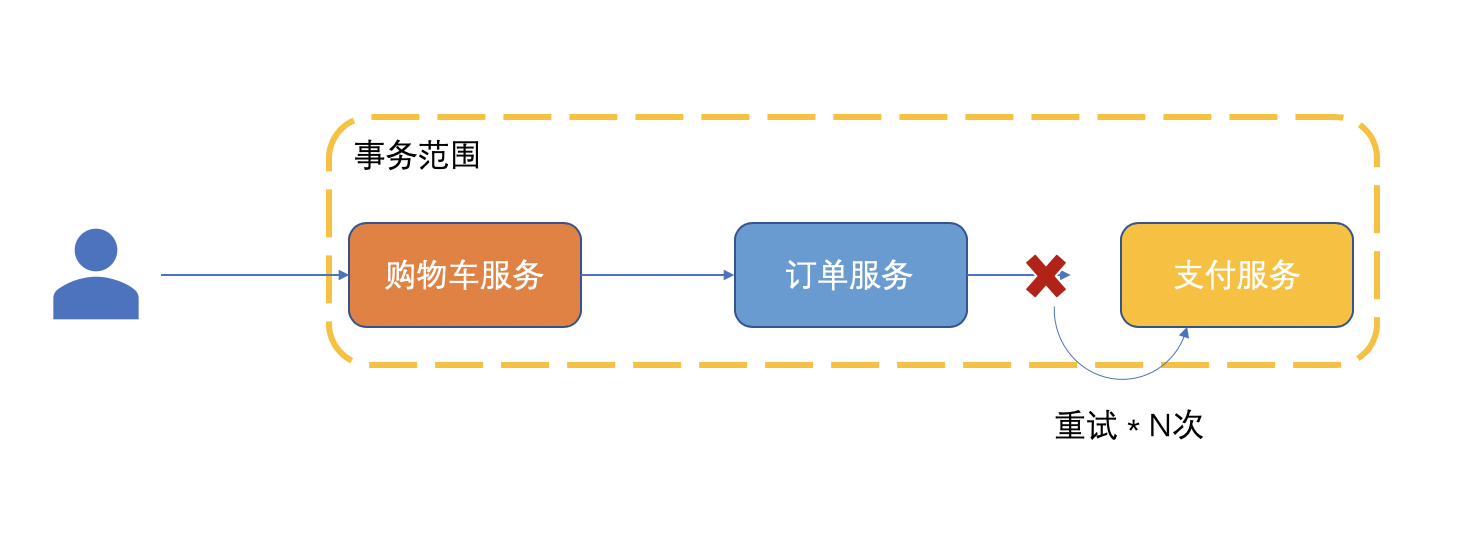
可能你会问,之前也看到过「补偿」和「事务补偿」或者「重试」,它们之间的关系是什么?
你其实可以不用太纠结这些名字,从目的来说都是一样的。就是一旦某个操作发生了异常,如何通过内部机制将这个异常产生的「不一致」状态消除掉。
:在Z哥看来,不管用什么方式,只要通过额外的方式解决了问题都可以理解为是「补偿」,所以「事务补偿」和「重试」都是「补偿」的子集。前者是一个逆向操作,而后者则是一个正向操作。
只是从结果来看,两者的意义不同。「事务补偿」意味着“放弃”,当前操作必然会失败。
「重试」则还有处理成功的机会。这两种方式分别适用于不同的场景。
因为「补偿」已经是一个额外流程了,既然能够走这个额外流程,说明时效性并不是第一考虑的因素,所以做补偿的核心要点是:宁可慢,不可错。
因此,不要草率的就确定了补偿的实施方案,需要谨慎的评估。虽说错误无法100%避免,但是抱着这样的一个心态或多或少可以减少一些错误的发生。
二、「补偿」该怎么做?
做「补偿」的主流方式就前面提到的「事务补偿」和「重试」,以下会被称作「回滚」和「重试」。
我们先来聊聊「回滚」。相比「重试」,它逻辑上更简单一些。
「回滚」
Z哥将回滚分为2种模式,一种叫「显式回滚」(),一种叫「隐式回滚」()。
最常见的就是「显式回滚」。这个方案无非就是做2个事情:
首先要确定失败的步骤和状态,从而确定需要回滚的范围。一个业务的流程,往往在设计之初就制定好了,所以确定回滚的范围比较容易。但这里唯一需要注意的一点就是:如果在一个业务处理中涉及到的服务并不是都提供了「回滚接口」,那么在编排服务时应该把提供「回滚接口」的服务放在前面,这样当后面的工作服务错误时还有机会「回滚」。
其次要能提供「回滚」操作使用到的业务数据。「回滚」时提供的数据越多,越有益于程序的健壮性。因为程序可以在收到「回滚」操作的时候可以做业务的检查,比如检查账户是否相等,金额是否一致等等。
由于这个中间状态的数据结构和数据大小并不固定,所以Z哥建议你在实现这点的时候可以将相关的数据序列化成一个json,然后存放到一个nosql类型的存储中。
「隐式回滚」相对来说运用场景比较少。它意味着这个回滚动作你不需要进行额外处理,下游服务内部有类似“预占”并且“超时失效”的机制的。例如:
分布式系统关注点——99%的人都能看懂的“补偿”以及最佳实践