
把Excel文件导入关系数据库是数据分析业务中经常要做的事情,但许多Excel文件的格式并不规整,需要事先将其中的数据结构化后再用SQL语句写入数据库. Java程序猿经常选择使用POI或者HSSFWorkbook等第三方类库来实现,通常都要硬编码,如果碰到格式复杂的表格,解析工作量还会成倍增加,Java没有表格对象,总要利用集合加实体类去实现,导致代码冗长,不通用。集算器的SPL是专业处理结构化数据的语言,它能够轻松读取Excel数据,然后结构化成“序表”后导入数据库。使用SPL语言后,以往需要编写数千行代码才能完成Excel的数据结构化入库工作,现在只需要不到10行代码就可以胜任,简单情况下甚至只需要2、3行代码。
而关于导出,有时我们需要用程序来自动生成Excel文件,但Excel本身带的VBA并不好用,集算器作为数据处理工具实现这个需求就会方便很多。
本文中用到的函数请参看集算器文档《函数参考》。
下面我们就来了解一下集算器是如何对表格数据进行导入或导出的:
<>强导入
<强> 1,普通行式
<强>表格样式:
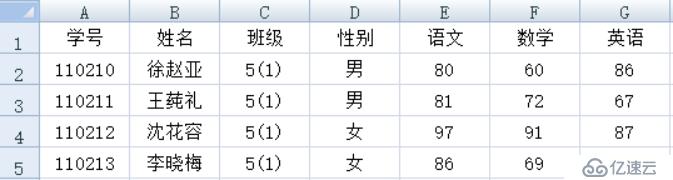
<强>集算器脚本:
2、多行表头行式
表格样式:
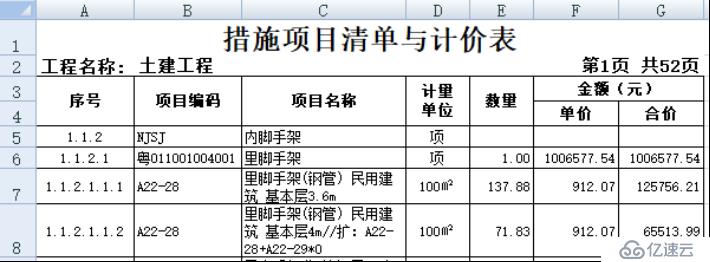
集算器脚本:

脚本说明:
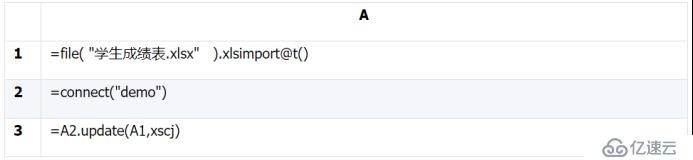
A1:打开文件并导入数据成序表,参数“1,5”表示读第一个 sheet,从第 5 行开始读,一直读到文件结尾;
A2:将 A1 中读到的序表列名依次改为“序号、项目编码、项目名称、计量单位、数量、单价、合价”,即要存入的数据表的列名。
导入效果:
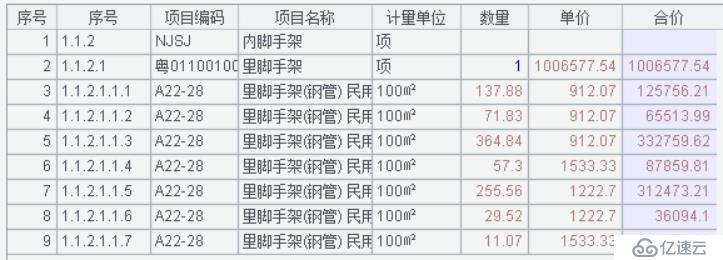
3、自由格式
表格样式:
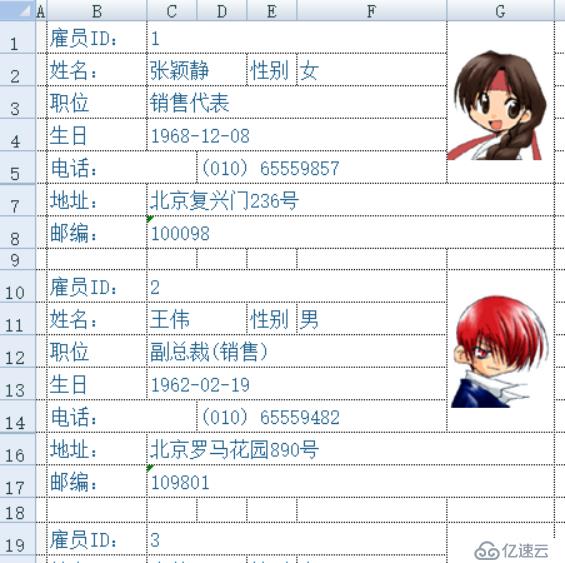
集算器脚本:

脚本说明:
A1:创建列名为“雇员 ID, 姓名, 性别, 职位, 生日, 电话, 地址, 邮编”的空序表
A2: 打开 Excel 数据文件
A3:定义雇员信息所在单元格列号序列
B3:定义雇员信息所在单元格行号序列
A4:用 for 循环读取每个雇员信息
B4:A3.(~/B3(#))先算出当前雇员单元格编号序列, 再读出这些单元格值组成雇员信息序列。第一次循环时为 [C1,C2,F2,C3,C4,D5,C7,C8],第二次循环时为[C10,C11,F11,C12,C13,D14,C16,C17]……每次行号加 9。$[A2.xlscell()与“A2.xlscell (“;相同,都是表示一个字符串,它的好处是在IDE中编写程序时,如果A2单元格的编号发生了变化,美元(A2。xlscell()中的A2会自动变化,比如在A2前插入了一行,这个表达式就会变成美元(A3。null




