
参考刘鹏的《实战Hadoop》一书,按照Hadoop 0.20.2几个注意的地方。
第一,首先理解Hadoop中的几个后台进程。
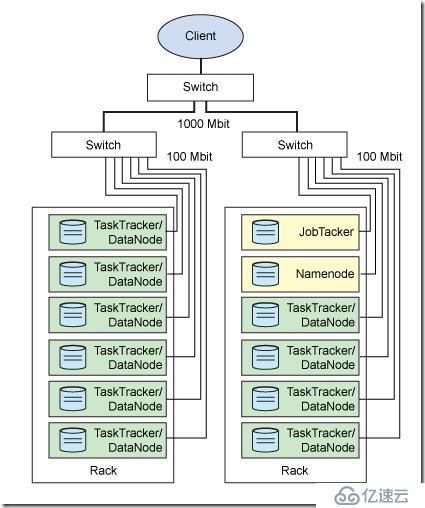
NameNode,二级NameNode, JobTracker, TaskTracker, DataNode这几个角色。
NameNode:负责如何切分数据块,和切完放哪个节点。它对内存和I/O集中管理。
这个进程部署在主节点上,是一个单点,它挂了整个系统都挂了。
二级NameNode:和NameNode一样,辅助程序。每个集群都有一个,它与NameNode进行通讯,定期保存HDFS元数据快照,当NameNode故障可以作为备用NameNode使用。它也是部署在主节点上。
JobTracker负责调度作业,它决定哪些文件由哪些节点运行,并且监听TaskTracker发送来的心跳。当收不到心跳,即认为某个任务失败,就会决定重启任务。每个集群只有一个JobTracker。它是部署在主节点上的。
上述三个进程都是部署在主节点上的,而TaskTracker和DataNode进程进程是集群中各个几点都需要部署的。
DataNode负责将HDFS数据块读写到本地文件系统。当客户端读写某个数据库的时候,由NameNode告诉客户端去那个DataNode进行,然后客户端直接与这个DataNode的服务器通信,并操作相关的数据块。
TaskTracker也是位于从节点的,它负责独立执行具体的任务,每个从节点只能有一个TaskTracker,但是每个TaskTracker可以产生多个Java虚拟机,用于并行处理多个map和reduce认为.TaskTracker还会和JobTracker交互,JobTasker负责分配任务,并且检测TaskTracker的心跳,如果没有心跳,就认为已经崩溃,并将认为分配给其他的TaskTracker。
各个进程的部署图如下:
具体的安装环节,可以参考书中的步骤,但是有几个点需要注意。
主机和从机统一创建专门的运行Hadoop的用户网格,设置SSH的免密码登陆机制,可以参考http://chenlb.iteye.com/blog/211809。将所有的机器上的公钥文件上里的内容,都统一整合到一个authorized_keys文件,以此实现互相免密码登陆SSH。
启动Hadoop的时候,注意要以网格用户登录,在网格用户的主目录下进行操作,有时权限的问题,此时要注意将主机和从机的Hadoop文件夹的主人设置为网格用户和组。执行乔恩- r网格:网格/home/grid/hadoop-1.2.1 ,,(此处为hadoop的放置目录,这里要使用根用户修改)
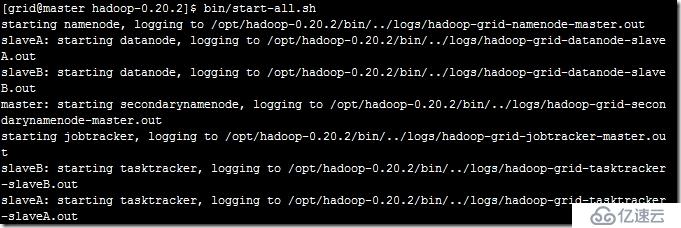
然后可以到hadoop的文件夹中的本目录下启动开始。sh,可以看到如下的信息,说明启动成功。
此时还可以通过运行命令查看进程的启动情况,在主机上运行jdk中的jps文件,可以看到如下:
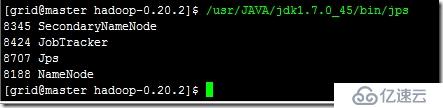
在从节点运行相同的命令,可以看到

至此,说明安装Hadoop已经成功了。




