
<强>集群规模计算
集群规模取决于用户数据及应用需求,最终规划值为以下各种计算方式得出的最小集群规模的最大值
?容量需求
-估算相对容易且准确
-大多数案例可以通过容量来决定集群规模
?计算需求
-准确的估算计算资源只能通过小规模测试并合理估算
?其他资源限制
,如用户MapReduce应用可能对内存等资源有特殊要求,且单节点可配置资源相对有限,则集群最小规模需满足用户此类资源要求
<>强网络建议
?建议使用万兆网络或更高速度网络
,如要充分利用磁盘并行操作带宽,至少需要万兆网络
- - - - - -即使带宽足够,使用高带宽网络也能带来性能提升
?对网络带宽敏感的场景:
- ETL类型或其他高输入输出数据量的MapReduce任务
- - - - - -对于空间或者电力资源有限的环境中,可使用大容量节点并配合高速度网络
——HBase等时延敏感类应用也对网络传输速度有要求
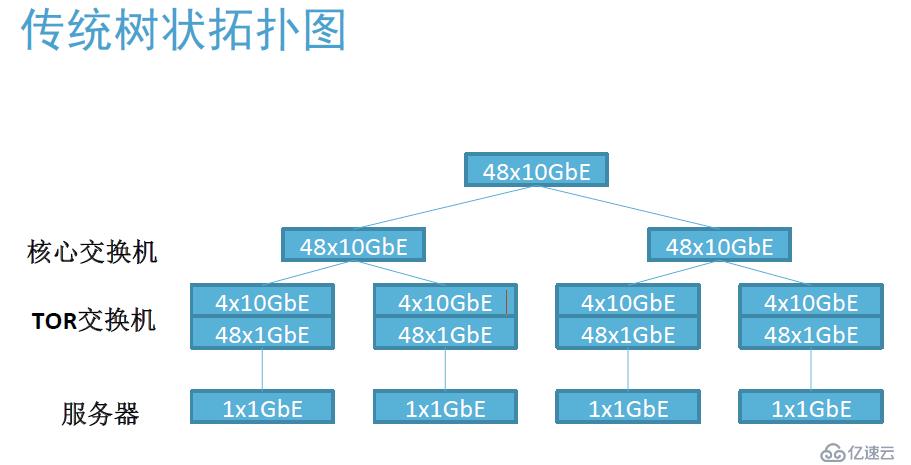
<强>传统树状网络
?网络超额(超额认购)
-通过增加层次扩充网络,但会有如下问题
-节点间网络距离增加
-网络超额问题恶化
?因此尽量采用超多端×××换机或扩充交换机背板扩充端口容量
-小型或中型网络可以使用双层树形架构
——仅通过顶层交换机上行端口和外部系统进行交互
,避免Hadoop的网络传输风暴污染外部网络
<强>组件架构
?管理节点(头/主节点):如NameNode,纱线及主等
-提供关键的,集中的,无替代的集群管理服务
,若该管理服务停止,则对应集群Hadoop服务停止
- - - - - -需要可靠性高的硬件设备
?数据节点(数据/工人/奴隶节点)
-处理实际任务,如数据存储,子任务执行等
-同节点运行多个服务,为保证局部性
,若该服务停止,则由其他节点自动代替服务
-硬件各部件皆可能损坏,但能方便的替换
?边缘节点(边缘节点)
-对外提供Hadoop服务代理以及包装
-作为客户端访问实际Hadoop服务
- - - - - -需要可靠性高的硬件设备
<强>管理节点硬件要求
?管理节点角色主要包括NameNode,二级NameNode,纱RM
-蜂巢元服务器以及蜂巢服务器通常部署在管理节点服务器上
-管理员服务器以及Hmaster可以选取数据节点服务器,由于一般负载有限,对节点无太大特殊要求
-所有HA候选服务器(活跃以及备用)使用相同配置
-通常对内存要求高但对存储要求低
?建议使用高端PC服务器甚至小型机服务器,以提高性能和可靠性
-双电源,冗余风扇,网卡聚合,突袭…
-系统盘使用RAID1
,由于管理节点数目很少且重要性高,高配置一般不是问题
<强>数据节点配置策略建议
?数量少但单点性能高的集群与数量多但单点性能低的集群
——一般而言,使用更多的机器而不是升级服务器配置
-采购主流的最“合”算配置的服务器,可以降低整体成本
-数据多分布可获得更好的扩展并行性能以及可靠性
- - - - - -需要考虑物理空间,网络规模以及其他配套设备等综合因素来
?考虑集群服务器数目
-计算密集型应用考虑使用更好的CPU以及更多的内存
<强>内存需求计算
?需要大内存的主节点角色:
- NameNode,二级NameNode,纱,Hbase Regionserver
?节点内存算法:
-大内存角色内存相加
-计算类应用需要大内存,如火花/黑斑羚建议至少256 gb内存
<强>硬盘容量选择
?通常建议使用更多数目的硬盘
-获得更好的并行能力
- - - - - -不同的任务可以访问不同的磁盘
- 8个1.5 tb的硬盘性能好于6个2 tb的硬盘
-除去数据永久存储需求外,一般建议预留20%至30%的空间用于存储临时数据
?MapReduce任务中间数据
?实际部署中每服务器配备12个硬盘非常常见
-单节点存储容量最大值不超过48结核病
<强>存储服务需求
数据源 Hadoop方式物理存储容量 数据节点数量 原始文件,数据量625吨 625年结核病 3(复制份数) 0.3(压缩比)/80%(硬盘利用率)=703结核病(只存放明细数据,无表,无先生) 按30 t每节点703 tb/30 * 1.05(冗余度)=25台 Hbase和卡桑德拉 数据服务:假设历史数据量为2.6吨,每日增量为55 g,数据保留365天,3副本使用压缩时:(2.6 + 0.055



