先生编程模型
先生编程模型主要分为五个步骤:输入,映射,分组,规约,输出。
-
<李>
输入(InputFormat):
主要包含两个步骤,数据分片,迭代输入
<代码>数据分片(getSplits):数据分为多少个分裂,就有多少个地图任务;
单个分裂的大小,由设置的split.minsize和split.maxsize决定;
公式为最大{minsize,最小{最大容量,blocksize}};
hadoop2.7.3之前blocksize默认64,之后默认128米。
决定了单个分裂大小之后,就是主机选择,一个分裂可能包含多个块(将minsize设置大于128米);
而多个块可能分布在多个主机节点上(一个块默认3备份,如果4个块就可能在12个节点),getsplits会选择包含数据最多的一部分主机。
由此可见,为了让数据本地话更合理,最好是一个块一个的任务,也就是说分裂大小跟块大小一致。
getSplits会产生两个文件
的工作。分裂:存储的主要是每个分片对应的HDFS文件路径,和其在HDFS文件中的起始位置,长度等信息(地图任务使用,获取分片的具体位置);
job.splitmetainfo:存储的则是每个分片在分片数据文件的工作。中分裂的起始位置,分片大小和主机等信息(主要是作业初始化时使用,用于地图任务的本地化)。
迭代输入:迭代输入一条条的数据,对于文本数据来说,关键就是行号,当价值前行文本。
李
<李>映射(地图):正常的地图操作,将一对kv映射成为另外一对kv李
<李>分组(分区):按照设置的减少个数来进行分组,getPartitions共三个参数:k、v, partitionnum;
默认按照HashPartition,如果需要全排的序,也可以设置TotalOrderPartitioner,它会采样一部分数据排序后设置R 1 (R是减少个数)个分割点,保证地图任务生成的R个文件的文件与文件之间的数据都是有序的,减少只需要对单个文件内部再排序即可。 <李>规约(减少):减少做聚合处理。 <李>输出(OutputFormat):
一件事情是检查输出目录是否存在,如果存在则报错;
另一件事情是将数据输出到临时目录。
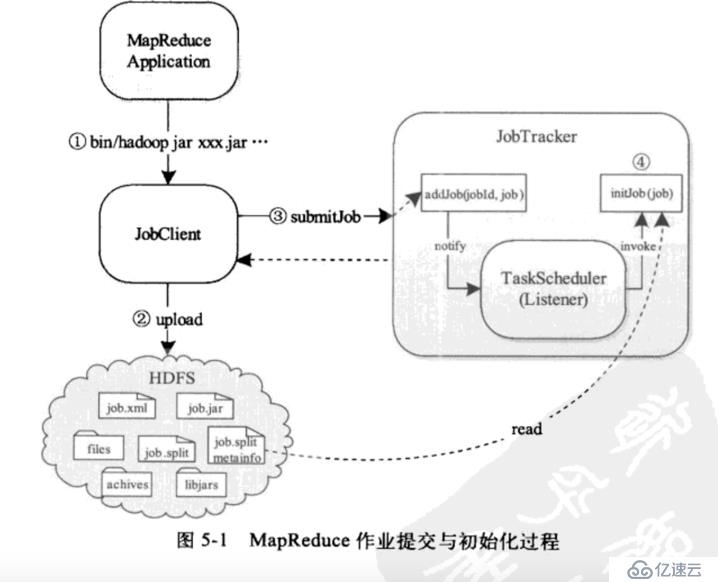
作业提交及初始化
-
<李>作业提交与初始化大概分为4个步骤:执行提交,端上传文件到hdfs,客户机与JobTracker通信提交任务,JobTracker通知TaskScheduler初始化任务。
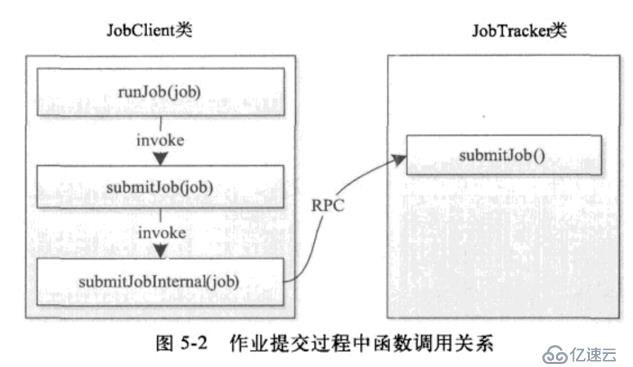
<李> JobClient与JobTracker的通信过程如下两所示
 <李>作业提交时序图
<李>作业提交时序图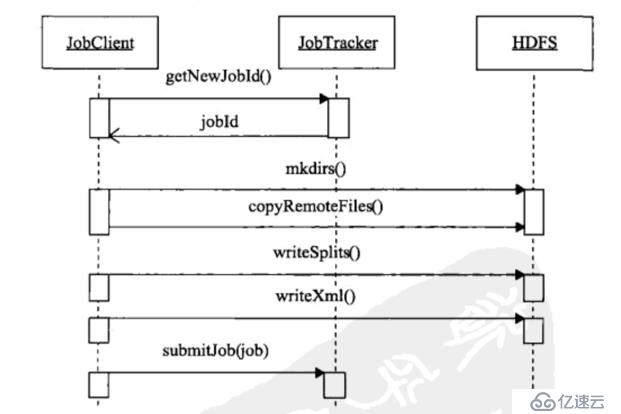
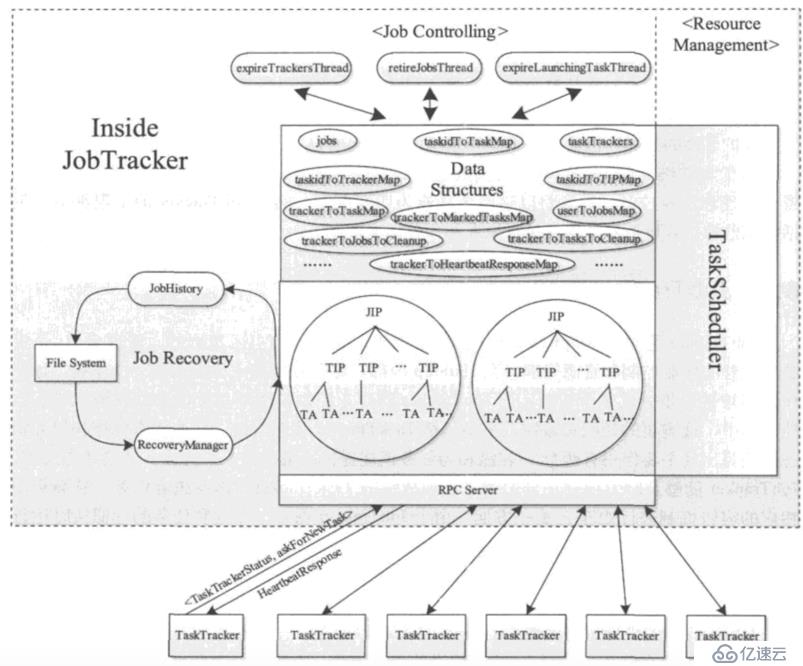
JobTracker与TaskTracker
-
<李> JobTracker主要负责作业的运行时管理,以三级树的方式进行管理:首先会给作业初始化一个对象JobInProgress,初始化后每个任务有个TaskInProgress,每个任务对应多个TaskAtempt。其中一个助教成功则此TI成功,所有钛成功则此工作成功
 先生编程模型及V1先生讲解
先生编程模型及V1先生讲解