
介绍 <李> #, - *安康;编码:utf-8 - * -
“““
Created Feb 28 10:30:56 2021
@author:可以叫我才哥
“““
import 请求
import 再保险
import pandas as pd
#,获取全部板块及板块id=url & # 39; http://quotes.money.163.com/old/查询=hy001000&数据类型=HS_RANK& sort=PERCENT&订单=desc&数=24,页面=0 & # 39;
时间=r requests.get (url)
html =r.text
#,替换非字符为空,便于下面的正则
时间=html re.sub (& # 39; \ & # 39; & # 39; & # 39;, html)
#,正则获取,板块及id所在区域
时间=labelHtml re.findall (" # 39; & lt;/span>主要行业\(新\)& lt;/a> (. * ?) & lt;/span>证监会行业\(新\)& # 39;,html) [0]
#,正则板块和id,结果为由元组组成的列的表
时间=label re.findall (" # 39;“qid=?hy。* ?)“qquery=? ?“title=?. * ?)“祝辞& # 39;,labelHtml)
#,转化为dataframe类型
时间=dfLabel pd.DataFrame(标签、列=[& # 39;id # 39; & # 39;板块& # 39;])
#,根据板块id和翻页获取页面数据(json格式)
def get_json (hy_id,页面):=,query & # 39; PLATE_IDS: & # 39;, +, str (hy_id)
,params={
& # 39;才能举办# 39;:,& # 39;http://quotes.money.163.com/hs/service/diyrank.php& # 39;
& # 39;才能页面# 39;:,页面,
& # 39;才能查询# 39;:,查询,
& # 39;才能领域# 39;:,& # 39;不,标志,名称,价格,百分比,上下按钮,FIVE_MINUTE,开放,YESTCLOSE,高,低,体积,营业额,HS,磅,世行,ZF, PE、MCAP, TCAP, MFSUM, MFRATIO.MFRATIO2, MFRATIO.MFRATIO10, SNAME,代码,ANNOUNMT UVSNEWS& # 39;,, #你可以不用这么多字段
& # 39;才能排序# 39;:,& # 39;% # 39;
& # 39;才能订单# 39;:,& # 39;desc # 39;
& # 39;才能算# 39;:,& # 39;24 & # 39;
& # 39;才能类型# 39;:,& # 39;查询# 39;
,,}=,url & # 39; http://quotes.money.163.com/hs/service/diyrank.php?& # 39;=,,r requests.get (url, params=参数)=,,j r.json ()
,
return j
#,空列表用于存取每页数据
时间=dfs []
#,遍历全部板块
for hy_id板块,拷贝dfLabel.values:
,#获取页数=,,j get_json (hy_id, 0)=,pages j [& # 39; pagecount& # 39;】
,
,for page 拷贝范围(页面):
时间=j 才能;get_json (hy_id,页面)=data 才能;j[& # 39;列表# 39;】
时间=df 才能;pd.DataFrame(数据)
df才能[& # 39;板块& # 39;],=,板块
dfs.append才能(df)
,打印(f # 39;已爬取{len (dfs)}个板块数据& # 39;)
时间=result pd.concat (dfs) 2。excel树状图
2.1。简单的树状图
2.2。带有增长率的树状图
今天就跟大家聊聊有关使用python怎么爬取最新的股票数据,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
1。python爬取网易财经不同板块股票数据
目标网址:
http://quotes.money.163.com/old/查询=hy010000&数据类型=HS_RANK& sort=PERCENT&订单=desc&数=24,页面=0
由于这个爬虫部分比较简单,这里不做过多赘述,仅介绍一下思路并附上完整代码供大家参考。
爬虫思路:
请求目标网站数据,解析出主要行业(新)的数据:行业板块名称及对应的id(如金融,hy010000)
<李>根据行业板块对应id构造新的行业股票数据网页
<李>由于翻页网址不变,按照《》的里的套路找到股票列表数据的真实地址
<李>代入参数,获取全部页数,然后翻页爬取全部数据
爬虫代码:
2。excel树状图
excel树状图是在office2016级之后版本中新加的图表类型,想要绘制需要基于此版本及之后的版本哦。
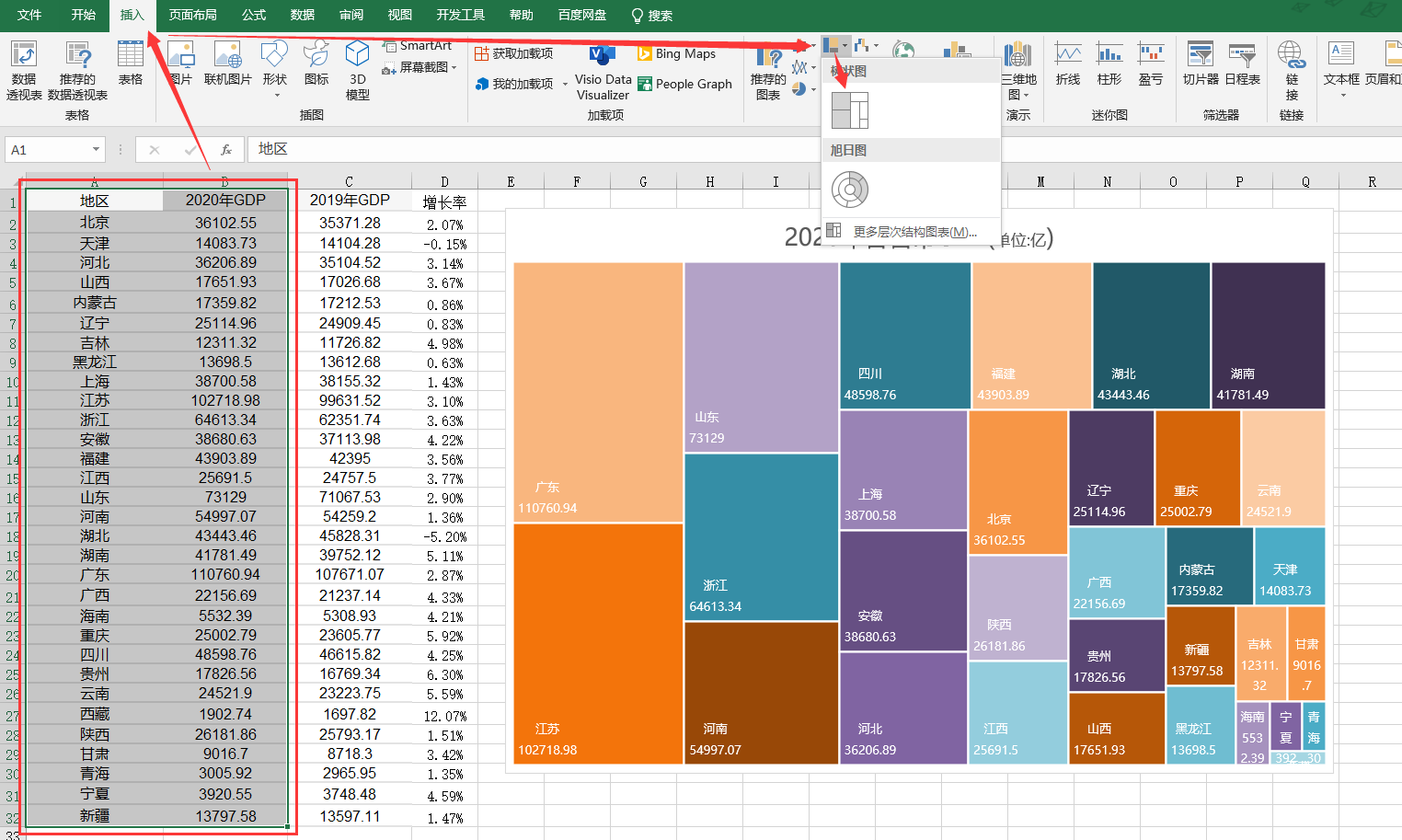
2.1。简单的树状图
简单的树状图绘制流程:框选数据→插入→图表→选中树状图,即可。
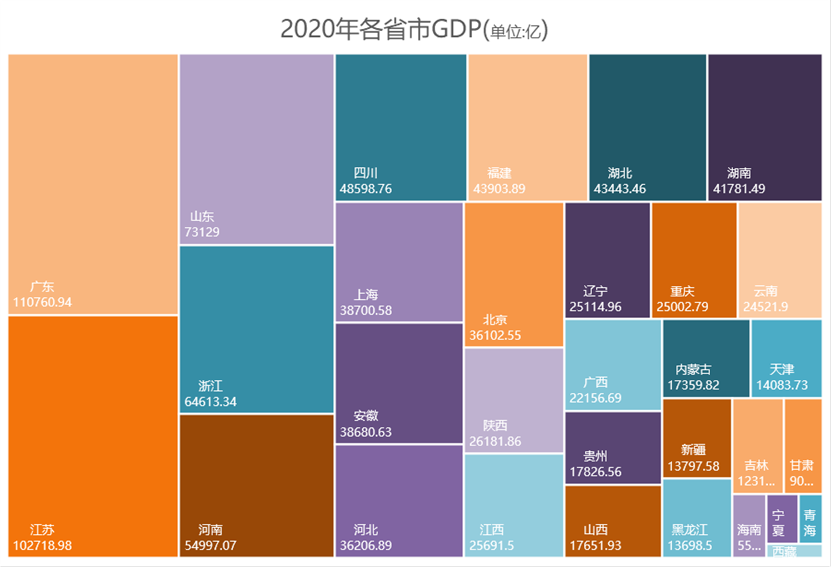
以下图为例,在树状图中,每个色块代表一个省份,色块面积大小则由其GDO值大小决定。
2.2。带有增长率的树状图
我们发现,在基础的树状图中,色块颜色除了区别色块之外并没有其他特殊含义。拿GDP来说,除了值之外我们一般也会去看其增长率,那么是否可以让色块颜色和增长率有关联呢?




