机器学习分两大类,有监督学习(监督学习)和无监督学习(无监督学习)。有监督学习又可分两类:分类(分类。)和回归(回归),分类的任务就是把一个样本划为某个已知类别,每个样本的类别信息在训练时需要给定,比如人脸识别,行为识别,目标检测等都属于分类。回归的任务则是预测一个数值,比如给定房屋市场的数据(面积,位置等样本信息)来预测房价走势。而无监督学习也可以成两类:聚类(集群)和密度估计(密度估计),聚类则是把一堆数据聚成弱干组,没有类别信息;密度估计则是估计一堆数据的统计参数信息来描述数据,比如深度学习的遏制。
根据机器学习实战讲解顺序,先学习K近邻法(K最近Neighbors-KNN)
K近邻法是有监督学习方法,原理很简单,假设我们有一堆分好类的样本数据,分好类表示每个样本都一个对应的已知类标签,当来一个测试样本要我们判断它的类别是,就分别计算到每个样本的距离,然后选取离测试样本最近的前K个样本的标签累计投票,得票数最多的那个标签就为测试样本的标签。
例子(电影分类):

(图一)
(图一)中横坐标表示一部电影中的打斗统计个数,纵坐标表示接吻次数。我们要对(图一)中的问号这部电影进行分类,其他几部电影的统计数据和类别如(图二)所示:
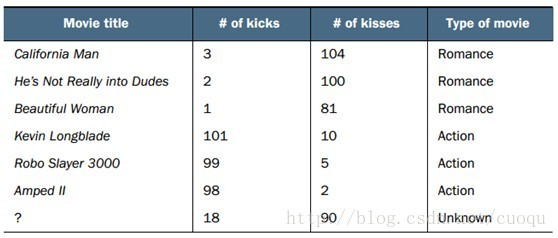
(图二)
从(图二)中可以看出有三部电影的类别是浪漫,有三部电影的类别是行动,那如何判断问号表示的这部电影的类别?根据资讯原理,我们需要在(图一)所示的坐标系中计算问号到所有其他电影之间的距离。计算出的欧式距离如(图三)所示:
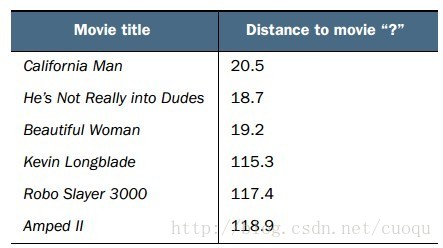
(图三)
,,,,由于我们的标签只有两类,那假设我们选K=6/2=3,由于前三个距离最近的电影都是浪漫,那么问号表示的电影被判定为浪漫。
Python版
代码实战(本):
先来看看资讯的实现:
从numpy进口*
进口经营者
从操作系统导入listdir
def classify0(点、数据集、标签,k):
dataSetSize=数据集。形状[0]#获取一条样本大小
diffMat=瓷砖(点(dataSetSize, 1)) -数据集#计算距离
sqDiffMat=diffMat * * 2 #计算距离
sqDistances=sqDiffMat.sum(轴=1)#计算距离
距离=sqDistances * * 0.5 #计算距离
sortedDistIndicies=distances.argsort() #距离排序
classCount={}
因为我在范围(k):
voteIlabel=标签[sortedDistIndicies[我]]#前K个距离最近的投票统计
classCount [voteIlabel]=classCount.get (voteIlabel,0) + 1 #前K个距离最近的投票统计
sortedClassCount=排序(classCount.iteritems()、关键=operator.itemgetter(1)反向=True) #对投票统计进行排序
返回sortedClassCount[0][0] #返回最高投票的类别
之前
下面取一些样本测试资讯:
def file2matrix(文件名):
fr=开放(文件名)
numberOfLines=len (fr.readlines()) #文件中的行数
returnMat=0 ((numberOfLines 3) #矩阵恢复做准备
classLabelVector=[] #准备标签返回
fr=开放(文件名)
指数=0
线的fr.readlines ():
行=line.strip ()
listFromLine=line.split (“\ t”)
returnMat[指数:]=listFromLine (0:3)
classLabelVector.append (int (listFromLine [1]))
指数+=1
返回returnMat classLabelVector
def autoNorm(数据):
minVals=dataSet.min (0)
maxVals=dataSet.max (0)=maxVals - minVals范围
normDataSet=0(形状(数据集)
m=dataSet.shape [0]
normDataSet=数据集-瓦(minVals (m, 1))
normDataSet=normDataSet/瓷砖(范围,(m, 1) #元素明智的分裂
返回normDataSet,范围,minVals
def datingClassTest ():
荷瑞修=0.50 #持有50%
datingDataMat datingLabels=file2matrix (datingTestSet2.txt) # setfrom加载数据文件
normMat范围,minVals=autoNorm (datingDataMat)
m=normMat.shape [0]
numTestVecs=int (m *荷瑞修)
errorCount=0.0
因为我在范围(numTestVecs):
classifierResult=classify0 (normMat [i:], normMat numTestVecs: m,:, datingLabels (numTestVecs: m), 3)
打印”的分类器回来:% d,真正的答案是:% d % (classifierResult, datingLabels[我])
如果(classifierResult !=datingLabels[我]):errorCount +=1.0
打印”总错误率:% f % (errorCount/浮动(numTestVecs))
打印errorCount





