
这篇文章给大家分享的是有关Redis6.0为什么要引入多线程的内容。小编觉得挺实用的,因此分享给大家做个参考。一起跟随小编过来看看吧。
Redis6.0之前为什么采用单线程模型
严格地说,从Redis 4.0之后并不是单线程。除了主线程外,还有一些后台线程处理一些较为缓慢的操作,例如无用连接的释放、大 key 的删除等等。
单线程模型,为何性能那么高?
Redis作者从设计之初,进行了多方面的考虑。最终选择使用单线程模型来处理命令。之所以选择单线程模型,主要有如下几个重要原因:
Redis操作基于内存,绝大多数操作的性能瓶颈不在CPU
单线程模型,避免了线程间切换带来的性能开销
使用单线程模型也能并发的处理客户端的请求(多路复用I/O)
使用单线程模型,可维护性更高,开发,调试和维护的成本更低
上述第三个原因是Redis最终采用单线程模型的决定性因素,其他的两个原因都是使用单线程模型额外带来的好处,在这里我们会按顺序介绍上述的几个原因。
性能瓶颈不在CPU
下图是Redis官网对单线程模型的说明。大概意思是:Redis的瓶颈并不在CPU,它的主要瓶颈在于内存和网络。在Linux环境中,Redis每秒甚至可以提交100万次请求。

为什么说Redis的瓶颈不在CPU?
首先,Redis绝大部分操作是基于内存的,而且是纯kv(key-value)操作,所以命令执行速度非常快。我们可以大概理解成,redis中的数据存储在一张大HashMap中,HashMap的优势就是查找和写入的时间复杂度都是O(1)。Redis内部采用这种结构存储数据,就奠定了Redis高性能的基础。根据Redis官网描述,在理想情况下Redis每秒可以提交一百万次请求,每次请求提交所需的时间在纳秒的时间量级。既然每次的Redis操作都这么快,单线程就可以完全搞定了,那还何必要用多线程呢!
线程上下文切换问题
另外,多线程场景下会发生线程上下文切换。线程是由CPU调度的,CPU的一个核在一个时间片内只能同时执行一个线程,在CPU由线程A切换到线程B的过程中会发生一系列的操作,主要过程包括保存线程A的执行现场,然后载入线程B的执行现场,这个过程就是“线程上下文切换”。其中涉及线程相关指令的保存和恢复。
频繁的线程上下文切换可能会导致性能急剧下降,这会导致我们不仅没有提升处理请求的速度,反而降低了性能,这也是 Redis 对于多线程技术持谨慎态度的原因之一。
在Linux系统中可以使用vmstat命令来查看上下文切换的次数,下面是vmstat查看上下文切换次数的示例:
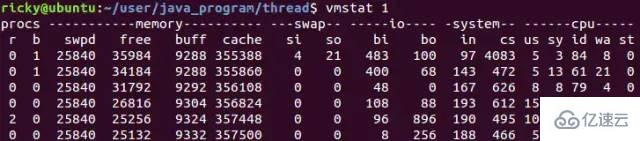 vmstat 1 表示每秒统计一次, 其中cs列就是指上下文切换的数目. 一般情况下, 空闲系统的上下文切换每秒在1500以下。
vmstat 1 表示每秒统计一次, 其中cs列就是指上下文切换的数目. 一般情况下, 空闲系统的上下文切换每秒在1500以下。
并行处理客户端的请求(I/O多路复用)
如上所述:Redis的瓶颈并不在CPU,它的主要瓶颈在于内存和网络。所谓内存瓶颈很好理解,Redis做为缓存使用时很多场景需要缓存大量数据,所以需要大量内存空间,这可以通过集群分片去解决,例如Redis自身的无中心集群分片方案以及Codis这种基于代理的集群分片方案。
对于网络瓶颈,Redis在网络I/O模型上采用了多路复用技术,来减少网络瓶颈带来的影响。很多场景中使用单线程模型并不意味着程序不能并发的处理任务。Redis 虽然使用单线程模型处理用户的请求,但是它却使用 I/O 多路复用技术“并行”处理来自客户端的多个连接,同时等待多个连接发送的请求。使用 I/O多路复用技术能极大地减少系统的开销,系统不再需要为每个连接创建专门的监听线程,避免了由于大量的线程创建带来的巨大性能开销。
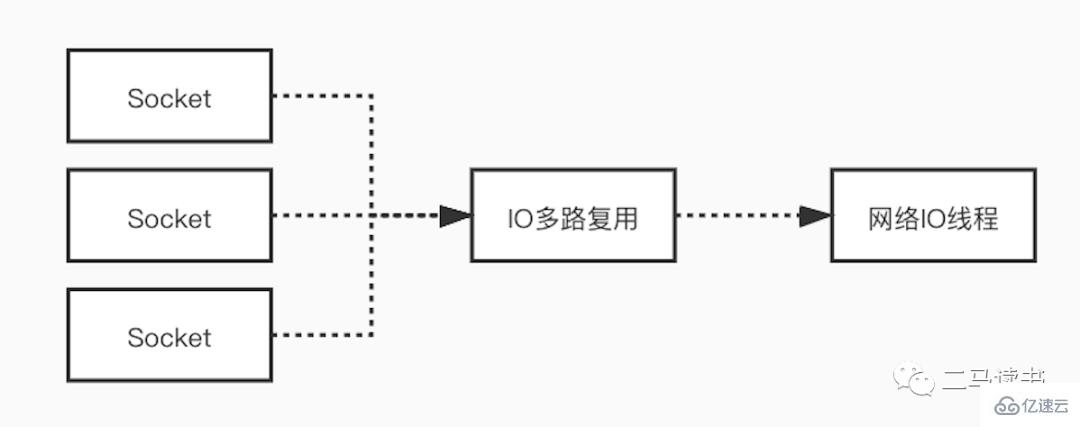
下面我们详细解释一下多路复用I/O模型。为了能更充分理解,我们先了解几个基本概念。
Socket(套接字):Socket可以理解成,在两个应用程序进行网络通信时,分别在两个应用程序中的通信端点。通信时,一个应用程序将数据写入Socket,然后通过网卡把数据发送到另外一个应用程序的Socket中。我们平常所说的HTTP和TCP协议的远程通信,底层都是基于Socket实现的。5种网络IO模型也都要基于Socket实现网络通信。




