在Python 3.5(含)以前,字典是不能保证顺序的,键值对一个先插入字典,键值对B后插入字典,但是当你打印字典的键列表时,你会发现B可能在一个的前面。
但是从Python 3.6开始,字典是变成有顺序的了。你先插入键值对,后插入键值对B,那么当你打印键列表的时候,你就会发现B在A的后面。
不仅如此,从Python 3.6开始,下面的三种遍历操作,效率要高于Python 3.5之前:
的关键字典
值的字典. values ()
键,值在字典. items ()
从Python 3.6开始,字典占用内存空间的大小,视字典里面键值对的个数,只有原来的30% ~ 95%。
Python 3.6到底对字典做了什么优化呢?为了说明这个问题,我们需要先来说一说,在Python 3.5(含)之前,字典的底层原理。
当我们初始化一个空字典的时候,CPython的底层会初始化一个二维数组,这个数组有8行3列,如下面的示意图所示:
my_dict={}
“‘
此时的内存示意图
[[,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -))
" 之前
现在,我们往字典里面添加一个数据:
my_dict['名称')=' kingname '
“‘
此时的内存示意图
[[,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(1278649844881305901,指向名字的指针,指向kingname的指针),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -))
" 之前
这里解释一下,为什么添加了一个键值对以后,内存变成了这个样子:
首先我们调用Python的哈希函数,计算名字这个字符串在当前运行时的哈希值:
在在在散列(“名字”)
1278649844881305901
特别注意,我这里强调了”当前运行时”,这是因为,Python自带的这个哈希函数,和我们传统上认为的哈希函数是不一样的.Python自带的这个哈希函数计算出来的值,只能保证在每一个运行时的时候不变,但是当你关闭Python再重新打开,那么它的值就可能会改变,如下图所示:
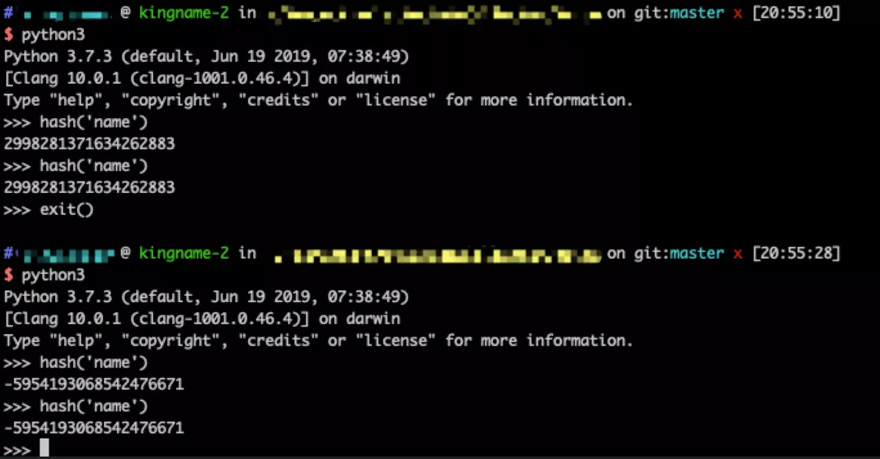
假设在某一个运行时里面,散列(“名字”)的值为1278649844881305901。现在我们要把这个数对8取余数:
在在在1278649844881305901 % 8
5
余数为5,那么就把它放在刚刚初始化的二维数组中,下标为5的这一行,由于名字和kingname是两个字符串,所以底层C语言会使用两个字符串变量存放这两个值,然后得到他们对应的指针。于是,我们这个二维数组下标为5的这一行,第一个值为名字的哈希值,第二个值为名字这个字符串所在的内存的地址(指针就是内存地址),第三个值为kingname这个字符串所在的内存的地址。
现在,我们再来插入两个键值对:
my_dict[‘年龄’]=26
my_dict[‘工资’]=999999
“‘
此时的内存示意图
[[-4234469173262486640,指向薪水的指针,指向999999年的指针),
(1545085610920597121,执行年龄的指针,指向26的指针),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -),
(1278649844881305901,指向名字的指针,指向kingname的指针),
(,- - - - - - - - - - - - - - - - - -),
(,- - - - - - - - - - - - - - - - - -))
" 之前
那么字典怎么读取数据呢?首先假设我们要读取年龄对应的值。
此时,Python先计算在当前运行时下面,年龄对应的散列值是多少:
在在在散列(“年龄”)
1545085610920597121





