<强>库普函数如下:
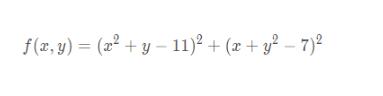
有四个全局最小解,且值都为0,这个函数常用来检验优化算法的表现如何:

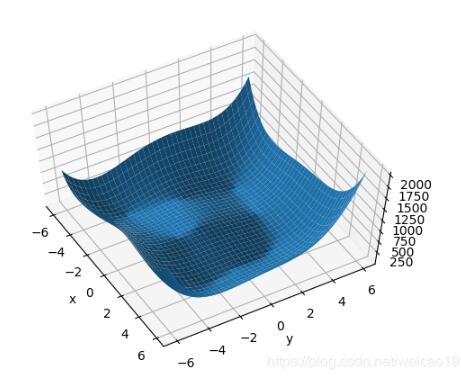
<强>可视化函数图像:
进口numpy np
从matplotlib进口pyplot plt
从mpl_toolkits。mplot3d进口Axes3D
def库普(x):
返回(x [0] * * 2 + x [1] - 11) * * 2 + x (x [0] + [1] * * 2 - 7) * * 2
x=np。不等(0.1 6 6)
y=np。不等(0.1 6 6)
X, Y=np。meshgrid (x, y)
Z=((X, Y))库普
无花果=plt.figure (“himmeblau”)
ax=fig.gca(投影=? d”)
斧子。plot_surface (X, Y, Z)
斧子。view_init (-30)
ax.set_xlabel (“x”)
ax.set_ylabel (y)
plt.show ()
结果:
<强>使用随机梯度下降优化:
进口火炬
def库普(x):
返回(x [0] * * 2 + x [1] - 11) * * 2 + x (x [0] + [1] * * 2 - 7) * * 2
#初始设置为0,0。
x=torch.tensor ([0。, 0。),requires_grad=True)
#优化目标是找到使库普函数值最小的坐标x [0], x [1],
#也就是x, y
#这里是定义亚当优化器,指明优化目标是x,学习率是1 e - 3
优化器=torch.optim。亚当([x], lr=1 e - 3)
一步的范围(20000):
#每次计算出当前的函数的值
pred=(x)库普
#当网络参量进行反馈时,梯度是被积累的而不是被替换掉,这里即每次将梯度设置为0
optimizer.zero_grad ()
#生成当前所在点函数值相关的梯度信息,这里即优化目标的梯度信息
pred.backward ()
#使用梯度信息更新优化目标的值,即更新x[0]和[1]
optimizer.step ()
#每2000次输出一下当前情况
如果步骤% 2000==0:
打印(“一步={},x={}, f (x)={}”。格式(一步,x.tolist (), pred.item ()))
输出结果:
一步=0,x=[0.0009999999310821295, 0.0009999999310821295], f (x)=170.0=2000步,x=[2.3331806659698486, 1.9540692567825317], f (x)=13.730920791625977=4000步,x=[2.9820079803466797, 2.0270984172821045], f (x)=0.014858869835734367=6000步,x=[2.999983549118042, 2.0000221729278564], f (x)=1.1074007488787174 e-08=8000步,x=[2.9999938011169434, 2.0000083446502686], f (x)=1.5572823031106964 e-09=10000步,x=[2.999997854232788, 2.000002861022949], f (x)=1.8189894035458565平台以及=12000步,x=[2.9999992847442627, 2.0000009536743164], f (x)=1.6370904631912708 e-11=14000步,x=[2.999999761581421, 2.000000238418579], f (x)=1.8189894035458565 e-12=16000步,x=[3.0, 2.0], f (x)=0.0=18000步,x=[3.0, 2.0], f (x)=0.0
从上面结果看,找到了一组最优解[3.0,2.0],此时极小值为0.0。如果修改张量变量x的初始化值,可能会找到其它的极小值,也就是说初始化值对于找到最优解很关键。
还是直接看代码吧!
进口火炬
进口torchvision
进口torchvision。变换,变换
进口torch.utils。数据的数据
进口matplotlib。pyplot作为plt
从torch.utils。数据导入数据集,DataLoader
熊猫作为pd导入
进口numpy np
从火炬。autograd导入变量
#数据集
火车=pd.read_csv (“Thirdtest.csv”)
#削减0坳标签
train_label=火车。iloc[:[0]] #只读取一列
# train_label=train.iloc (:, 0:3)
#削减1 ~ 16坳数据
train_data=https://www.yisu.com/zixun/train.iloc [: 1:]
#改变np
train_label_np=train_label.values
train_data_np=train_data.values
#改变张量
train_label_ts=torch.from_numpy (train_label_np)
train_data_ts=torch.from_numpy (train_data_np)
train_label_ts=train_label_ts.type (torch.LongTensor)
train_data_ts=train_data_ts.type (torch.FloatTensor)
打印(train_label_ts.shape)
print(类型(train_label_ts))
train_dataset=Data.TensorDataset (train_data_ts train_label_ts)
train_loader=DataLoader(数据集=train_dataset batch_size=64,洗牌=True)
#做一个网络
进口torch.nn。功能是f#激励函数都在这
类网(torch.nn.Module): #继承火炬的模块
def __init__(自我):
超级(净,自我). __init__() #继承__init__功能
自我。hidden1=torch.nn。线性(16日30)#隐藏层线性输出
自我。=torch.nn。3)线性(30日#输出层线性输出
def向前(自我,x):
#正向传播输入值,神经网络分析出输出值
x=F.relu (self.hidden1 (x) #激励函数(隐藏层的线性值)
x=self.out (x) #输出值,但是这个不是预测值,预测值还需要再另外计算
返回x
#净=()
#优化器=torch.optim.SGD (net.parameters (), lr=0.0001,动量=0.001)
# loss_func=torch.nn.CrossEntropyLoss()不是一个one-hotted #目标标签
# loss_list=[]
#时代的范围(500):
一步,# (bx的话)列举(train_loader):
#提出的话=变量(提出),变量(的话)
#的话=b_y.squeeze (1)
#输出=净(提出)
#损失=loss_func的话(输出)
# optimizer.zero_grad ()
# loss.backward ()
# optimizer.step ()
#如果时代% 1==0:
# loss_list.append(浮动(损失))
#打印(“时代,时代:““步骤”,一步,“失:浮动(损失))
#为每个优化器创建一个网
net_SGD=净()
net_Momentum=净()
net_RMSprop=净()
net_Adam=净()
网=[net_SGD net_Momentum、net_RMSprop net_Adam]
#定义优化器
LR=0.0001
opt_SGD=torch.optim.SGD (net_SGD.parameters (), lr=lr,动量=0.001)
opt_Momentum=torch.optim.SGD (net_Momentum.parameters (), lr=lr,动量=0.8)
opt_RMSprop=torch.optim.RMSprop (net_RMSprop.parameters (), lr=lr,α=0.9)
opt_Adam=torch.optim.Adam (net_Adam.parameters (), lr=lr,贝塔=(0.9,0.99))
优化器=[opt_SGD opt_Momentum、opt_RMSprop opt_Adam]
loss_func=torch.nn.CrossEntropyLoss ()
losses_his=[[]、[] [], []]
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null





