
前言
熊猫是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法,其中熊猫定义了系列和DataFrame两种数据类型,这使数据操作变得更简单.Series是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame是一种二维的数据结构,接近于电子表格或者mysql数据库的形式。
在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中。本文通过该例程介绍对大熊猫数据遍历的几种方法。
<强劲> . .在循环迭代方式
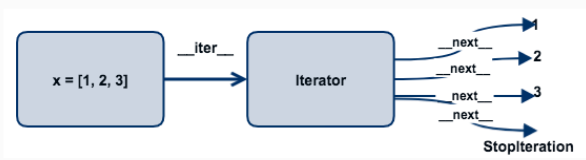
为语句是Python内置的迭代器工具,用于从可迭代容器对象(如列表,元组,字典,集合,文件等)中逐个读取元素,直到容器中没有更多元素为止,工具和对象之间只要遵循可迭代协议即可进行迭代操作。
具体的迭代的过程:可迭代对象通过__iter__方法返回迭代器,迭代器具有__next__方法,对循环不断地调用__next__方法,每次按序返回迭代器中的一个值,直到迭代到最后,没有更多元素时抛出异常抛出StopIteration (python自动处理异常)。迭代的优点是无需把所有元素一次加载到内存中,可以在调用一方法时逐个返回元素,避免出现内存空间不够的情况。
实现代码如下:
关于上述代码中范围的实现方法,我们也可根据迭代器协议自实现相同功能的迭代器(自带iter方法和第二方法)应用在为循环中,代码如下:
我们也可以通过列表解析的方式用更少的代码实现数据处理功能
<强> iterrows()生成器方式
iterrows是对dataframe行进行迭代的一个生成器,它返回每行的索引及包含行本身的对象。所谓生成器其实是一种特殊的迭代器,内部支持了迭代器协议.Python中提供生成器函数和生成器表达式两种方式实现生成器,每次请求返回一个结果,不需要一次性构建一个结果列表,节省了内存空间。
生成器函数:编写为常规的def语句,但是使用收益率语句一次返回一个结果,在每个结果之间挂起和继续它们的状态。
生成器表达式:类似列表解析,按需产生结果的一个对象。
iterrows()实现代码如下:
iterrows代码如下,收益率语句挂起该函数并向调用者发送回一组值:




