
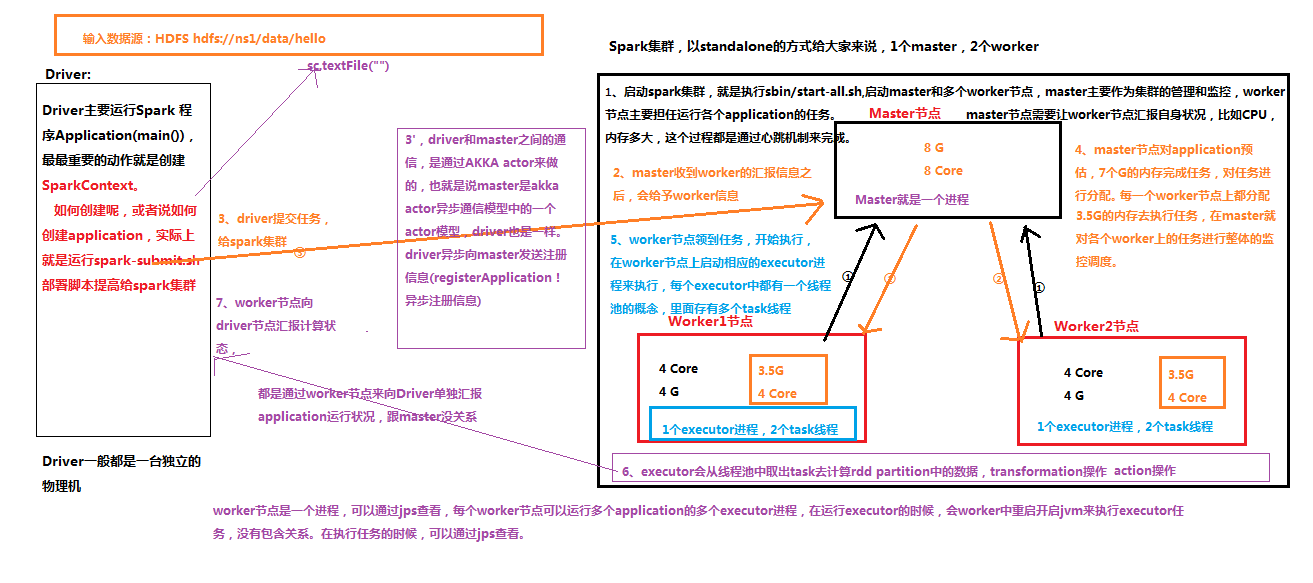
1。启动火花集群,就是执行sbin/start-all.sh,启动主和多个工人节点,掌握主要作为集群的管理和监控,工人节点主要担任运行各个应用的任务部分节点需要让工人节点汇报自身状况,比如CPU、内存多大,这个过程都是通过心跳机制来完成的
2.主收到工人的汇报信息之后,会给予职工信息
3.司机提交任务给火花集群(司机和主之间的通信是通过AKKAactor来做的,也就是说主是AKKAactor异步通信模型中的一个演员模型,司机也是一样,司机异步向母亲发送注册信息(registerApplication)异步注册信息)
4.主节点对应用程序预估,7个G的内存完成任务,对任务进行分配,每一个工人节点上都分配3.5 G的内存去执行任务,在主人就对各个工人上的任务进行整体的监控调度
5.工人节点领到任务,开始执行,在工人节点上启动相应的遗嘱执行人进程来执行,每个执行程序中都有一个线程池的概念,里面存有多个任务线程
6.执行人会从线程池中取出任务去计算rddpatition中的数据,转换操作,行动操作
7.工人节点向司机节点汇报计算状态
抽样:弹性分布式数据集,是一种集合,支持多种来源,有容错机制,可以被缓存,支持并行操作,一个抽样代表一个分区里的数据集
抽样有两种操作算子:
转换(转化):转换属于延迟计算,当一个抽样转换成另一个抽样时并没有立即进行转换,紧紧是记住了数据集的逻辑操作
操作(执行):触发火花作业的运行,真正触发转换算子的计算
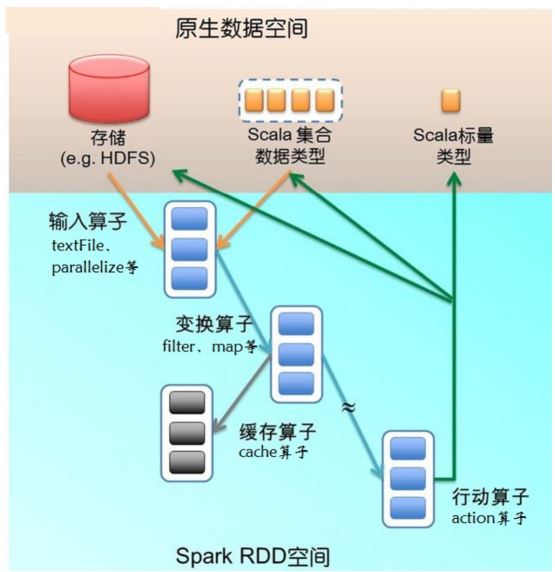
该图描述的是火花在运行转换中通过算子对抽样进行转换,算子是抽样中定义的函数,可以对抽样中的数据进行转换和操作。
输入:在火花程序运行中,数据从外部数据空间(如分布式存储:文本文件读取HDFS等,并行化方法输入Scala集合或数据)输入火花,数据进入火花运行时数据空间,转化为火花中的数据块,通过BlockManager进行管理
运行:在火花数据输入形成抽样后便可以通过变换算子,如过滤等。对数据进行操作并将抽样转换为新的抽样,通过行动算子,触发火花提交作业,如果数据需要复用,可以通过缓存算子,将数据缓存到内存
输出:程序运行结束数据会输出火花运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS),或Scala数据或集合中(收集输出到Scala集合,计数返回Scala int型数据)
<强>转换
地图(函数):返回一个新的分布式数据集,由每个原元素经过func函数转换后组成
过滤器(函数):返回一个新的数据集,由经过func函数
flatMap(函数):类似于地图,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)
样本(withReplacement、压裂、种子):根据给定的随机种子种子,随机抽样出数量为压裂的数据
联盟(otherDataset):返回一个新的数据集,由原数据集和参数联合而成
roupByKey ([numTasks]):在一个由(K、V)对组成的数据集上调用,返回一个(K, Seq [V])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你可以传入numTask可选参数,根据数据量设置不同数目的任务
reduceByKey (func (numTasks)):在一个(K、V)对的数据集上使用,返回一个(K、V)对的数据集,关键相同的值,都被使用指定的减少函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的。




