
如果能在头脑中构建一幅MySQL各组件之间如何协同工作的架构图,有助于深入理解MySQL服务器。下图展示了MySQL的逻辑架构图。
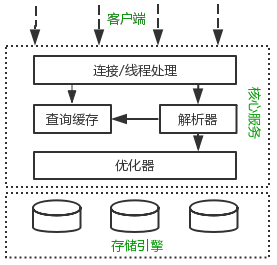
MySQL逻辑架构,来自:高性能MySQL
MySQL逻辑架构整体分为三层,最上层为客户端层,并非MySQL所独有,诸如:连接处理,授权认证,安全等功能均在这一层处理。
MySQL大多数核心服务均在中间这一层,包括查询解析,分析,优化,缓存,内置函数(比如:时间,数学,加密等函数)。所有的跨存储引擎的功能也在这一层实现:存储过程,触发器、视图等。
最下层为存储引擎,其负责MySQL中的数据存储和提取。和Linux下的文件系统类似,每种存储引擎都有其优势和劣势。中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差异。
MySQL使用基于成本的优化器,它尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。在MySQL可以通过查询当前会话的last_query_cost的值来得到其计算当前查询的成本。
示例中的结果表示优化器认为大概需要做6391个数据页的随机查找才能完成上面的查询。这个结果是根据一些列的统计信息计算得来的,这些统计信息包括:每张表或者索引的页面个数,索引的基数,索引和数据行的长度,索引的分布情况等等。
有非常多的原因会导致MySQL选择错误的执行计划,比如统计信息不准确,不会考虑不受其控制的操作成本(用户自定义函数,存储过程),MySQL认为的最优跟我们想的不一样(我们希望执行时间尽可能短,但MySQL值选择它认为成本小的,但成本小并不意味着执行时间短)等等。
这里last_query_cost的值是io_cost和cpu_cost的开销总和,它通常也是我们评价一个查询的执行效率的一个常用指标。
(1)它是作为比较各个查询之间的开销的一个依据。
(2)它只能检测比较简单的查询开销,对于包含子查询和联盟的查询是测试不出来的。
(3)当我们执行查询的时候,MySQL会自动生成一个执行计划,也就是query 计划,而且通常有很多种不同的实现方式,它会选择最低的那一个,而这个成本值就是开销最低的那一个。
(4)它对于比较我们的开销是非常有用的,特别是我们有好几种查询方式可选的时候。
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。




