
<强>并查集(Union-Find组):
一种用于管理分组的数据结构,它具备两个操作:(1)查询元素一个和元素b是否为同一组(2)将元素a和b合并为同一组。
注意:并查集不能将在同一组的元素拆分为两组。
<强>并查集的实现:
用树来实现。
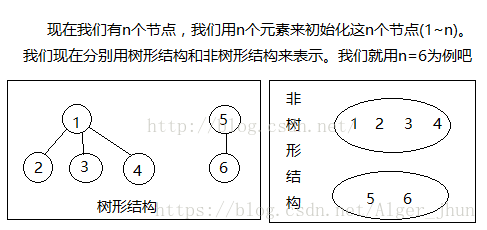
使用树形结构来表示以后,每一组都对应一棵树,然而我们就可以将这个问题转化为树的问题了,我们看两个元素是否为一组我们只要看这两个元素的根是否一致。显然,使用树形结构将问题简单化了。合并时是我们只需要将一组的根与另一组的根相连即可。
并查集的核心在于,一棵树的所有节点根节点都为一个节点。使用找到函数查询时,也是查询到这个节点的根节点。
<强>一行并查集:
实现:
<强>并查集的路径压缩: 在特殊情况下,这棵树是一条长长的树链,设链的最后一个结点为x,则每次执行找到(x)都会遍历整条链。效率十分的地下。改进方法很简单,只要把遍历过的结点都改成根的子结点,后面的查询就会变的快很多。 <强>并查集的复杂度 加入这两个优化之后,并查集的效率就非常高。对n个元素的并查集操作一次的复杂度是:O(α(n))。这里,α(n)是阿克曼(阿克曼)函数的反函数。效率要高于O (log n)。 不过这里O(α(n))是平均复杂度。也就是说,多次操作之后平均复杂度为O(α(n)),换而言之,并不是每一次操作都满足O(α(n))。 路径压缩后的优化代码: <>强实例分析: <强>题目:部落 在一个社区里,每个人都有自己的小圈子,还可能同时属于很多不同的朋友圈。我们认为朋友的朋友都算在一个部落里,于是要请你统计一下,在一个给定社区中,到底有多少个互不相交的部落?并且检查任意两个人是否属于同一个部落。 <强>输入格式: 输入在第一行给出一个正整数N (& lt;=104),是已知小圈子的个数。随后N行,每行按下列格式给出一个小圈子里的人: K p [1] [2]……P [K] 其中K是小圈子里的人数,p[我](i=1, . .,K)是小圈子里每个人的编号。这里所有人的编号从1开始连续编号,最大编号不会超过104 . 之后一行给出一个非负整数问(& lt;=104),是查询次数。随后问行,每行给出一对被查询的人的编号。
c语言数据结构之并查集总结




