
最近由于业务需要监控一些数据,虽然市面上有很多优秀的爬虫框架,但是我仍然打算从头开始实现一套完整的爬虫框架。
在技术选型上,我没有选择春天来搭建项目,而是选择了更轻量级的Vert.x。一方面感觉春天太重了,而Vert.x是一个基于JVM,轻量级,高性能的框架。它基于事件和异步,依托于全异步Java服务器网状的,并扩展了很多其他特性。
github地址:https://github.com/fengzhizi715/NetDiscovery
<强>一。爬虫框架的功能
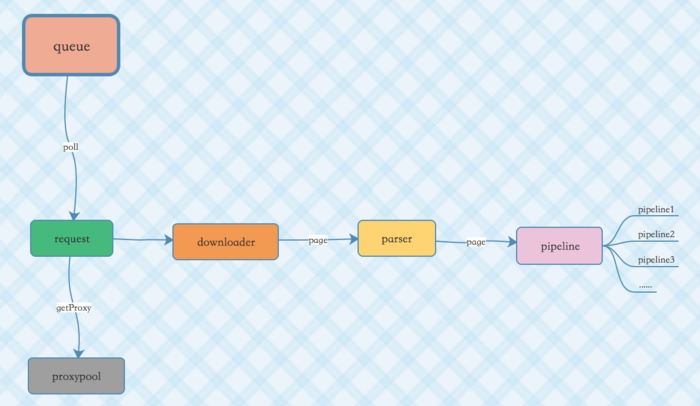
爬虫框架包含爬虫引擎(SpiderEngine)和爬虫(蜘蛛).SpiderEngine可以管理多个蜘蛛。
<强>蜘蛛
1.1在蜘蛛中,主要包含几个组件:下载器,队列,解析器,管道以及代理池IP (proxypool),代理池是一个单独的项目,我前段时间写的,在使用爬虫框架时经常需要切换代理IP,所以把它引入进来。
proxypool地址:https://github.com/fengzhizi715/ProxyPool
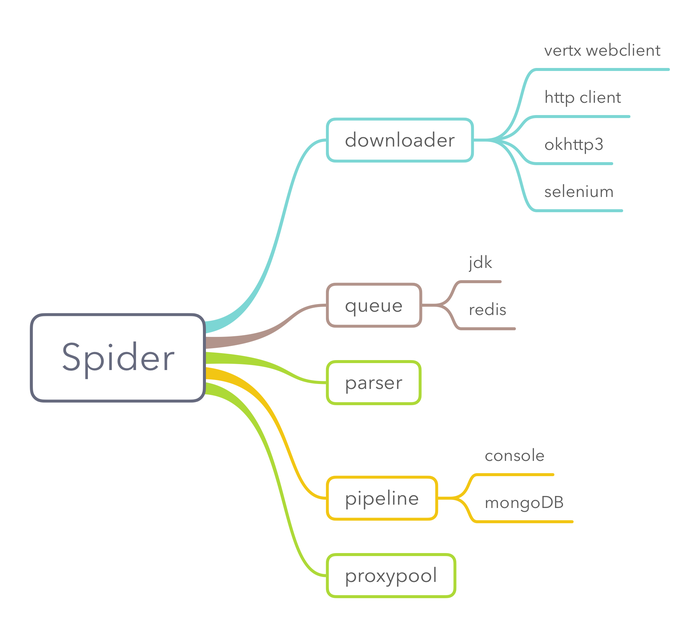
其余四个组件都是接口,在爬虫框架中内置了一些实现,例如内置了多个下载器(下载)包括vertx的webclient, http客户端,okhttp3、硒实现的下载器。开发者可以根据自身情况来选择使用或者自己开发全新的下载器。
下载器下载的方法会返回一个Maybe
在这里使用RxJava 2可以让整个爬虫框架看起来更加响应式:)
<强> 1.2 SpiderEngine
SpiderEngine可以包含多个蜘蛛,可以通过addSpider (), createSpider()来将爬虫添加到SpiderEngine和创建新的蜘蛛并添加到SpiderEngine。

在SpiderEngine中,如果调用了httpd(港口)方法,还可以监控SpiderEngine中各个蜘蛛。
1.2.1获取某个爬虫的状态
http://localhost{港口}/netdiscovery/蜘蛛/{spiderName}
类型:
1.2.2获取SpiderEngine中所有爬虫的状态
http://localhost{港口}/netdiscovery/蜘蛛/
类型:
1.2.3修改某个爬虫的状态
http://localhost{港口}/netdiscovery/蜘蛛/{spiderName}/状态
类型:文章
参数说明:
状态 作用 2 让爬虫暂停 3. 让爬虫从暂停中恢复 4 让爬虫停止




