jb51上面的资源还比较全,就准备用python来实现自动采集信息,与下载啦。
Python具有丰富和强大的库,使用urllib、再保险等就可以轻松开发出一个网络信息采集器!
下面,是我写的一个实例脚本,用来采集某技术网站的特定栏目的所有电子书资源,并下载到本地保存!
软件运行截图如下:
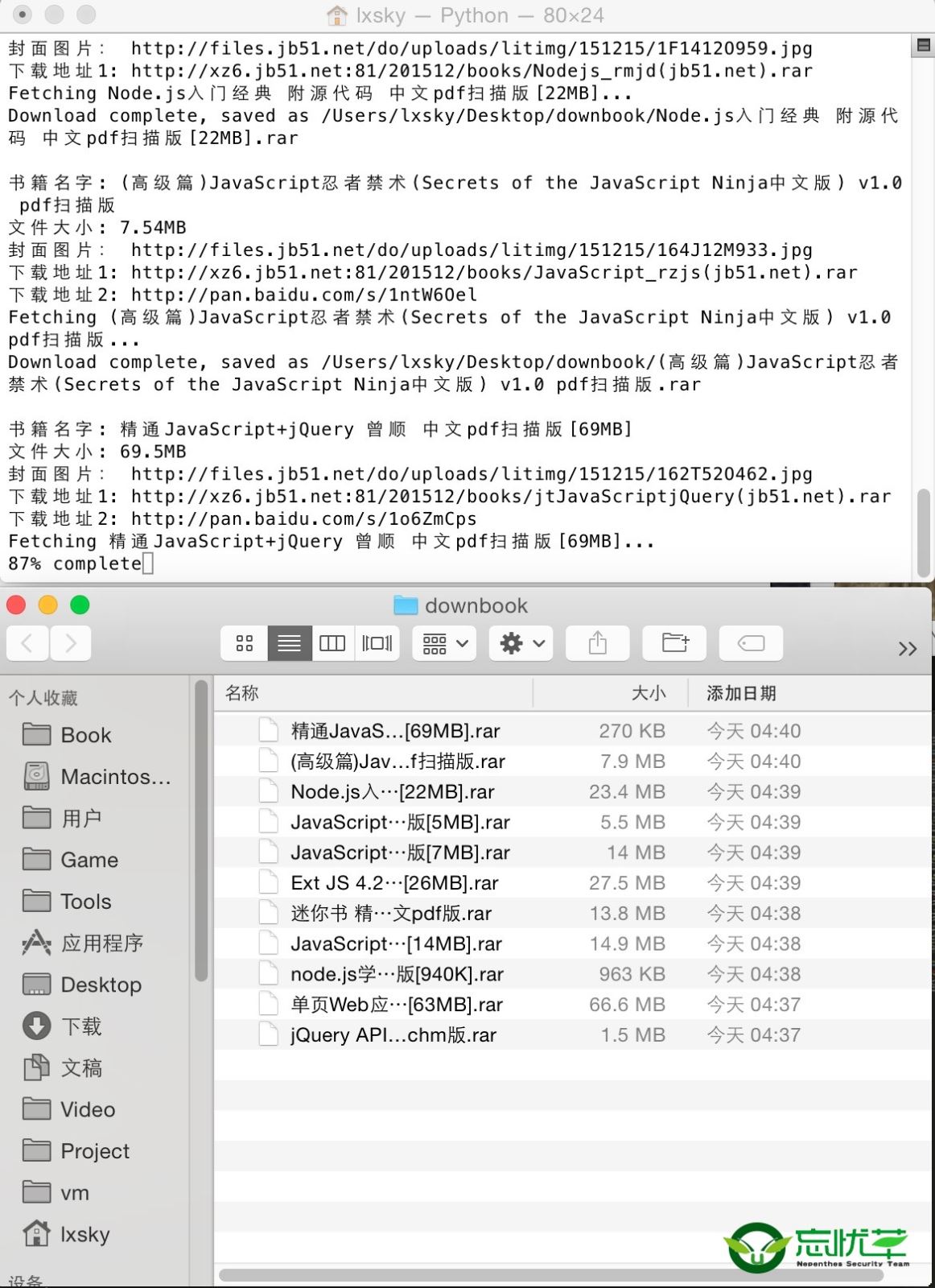
在脚本运行时期,不但会打印出信息到壳窗口,还会保存日志到txt文件,记录采集到的页面地址,书籍的名称,大小,服务器本地下载地址以及百度网盘的下载地址!
实例采集并下载的python栏目电子书资源:
# - * -编码:utf - 8 - *
进口再保险
进口urllib2
进口urllib
导入系统
进口操作系统
重载(系统)
sys.setdefaultencoding (“utf - 8”)
def getHtml (url):
请求=urllib2.Request (url)
页面=urllib2.urlopen(请求)
htmlcontent=page.read ()
#解决中文乱码问题
htmlcontent=htmlcontent.decode (“gbk”、“忽略”).encode (“use utf8”、“忽略”)
返回htmlcontent
def报告统计,blockSize totalSize):
%=int(计数* blockSize * 100/totalSize)
sys.stdout。写(r % d % % % % +“完成”)
sys.stdout.flush ()
def getBookInfo (url):
htmlcontent=getHtml (url);
#打印”htmlcontent=" htmlcontent;#您应该看到输出的html
# & lt; h2类=" h2user "祝辞crifan
regex_title=' & lt;硫化氢+ & # 63;itemprop=皀ame”祝辞(& # 63;术中;title> + & # 63;) & lt;/h2>”;
title=re.search (regex_title htmlcontent);
如果(标题):
title=title.group(“标题”);
打印”书籍名字:“、标题;
file_object.write(“书籍名字:‘+标题+ ' r ');
# & lt; li>书籍大小:& lt; itemprop跨度=拔募笮 钡脑?7.2 mb & lt;/li>
文件大?re.search (' & lt;跨越+ & # 63;itemprop=拔募笮 弊4?& # 63;术中;filesize> + & # 63;) & lt;/span>”, htmlcontent);
如果(文件大小):
文件大?filesize.group(“文件大小”);
打印”文件大小:“,文件大小;
file_object.write(“文件大小:“+文件大小+ ' r ');
# & lt; div类=" picthumb "祝辞& lt; a href=" https://www.yisu.com//img.jbzj.com/do/uploads/litimg/151210/1A9262GO2.jpg " target="平等"
bookimg=re.search (' & lt; div + & # 63;类=皃icthumb祝辞& lt; a href=" https://www.yisu.com/zixun/(P 。+ ?)“rel==捌降取薄巴獠縩ofollow”目标,htmlcontent);
如果(bookimg):
bookimg=bookimg.group (“bookimg”);
打印”封面图片:“,bookimg;
file_object.write(“封面图片:“+ bookimg + ' r ');
# & lt; li> & lt; a href=" http://xz6.jb51.net: 81/201512/书/JavaWeb100 (jb51.net) . rar”目标=捌降取痹诳嵩浦泄缧畔略? lt;/a> & lt;/li>
downurl1=re.search (' & lt; li> & lt; a href=" https://www.yisu.com/zixun/(P 。+ ?)“rel==捌降取薄巴獠縩ofollow”目标在酷云中国电信下载& lt;/a> & lt;/li>”, htmlcontent);
如果(downurl1):
downurl1=downurl1.group (“downurl1”);
打印”下载地址1:”downurl1;
file_object.write(“下载地址1:' + downurl1 + ' r ');
sys.stdout。写(“rFetching”+名称+“…n”)
标题=标题。替换(“,”);
标题=标题。替换(‘/?”);
saveFile='/用户/superl/桌面/pythonbook/' +标题+ . rar的;
如果os.path.exists (saveFile):
打印”该文件已经下载了!”;
其他:
urllib。urlretrieve (downurl1 saveFile reporthook=报告);
sys.stdout。写(“rDownload完整,保存为% s“% (saveFile) +“神经网络”)
sys.stdout.flush ()
file_object.write(“文件下载成功! r ');
其他:
打印”下载地址1不存在”;
file_error.write (url + ' r ');
file_error.write(标题+”下载地址1不存在!文件没有自动下载! r”);
file_error.write (' r ');
# & lt; li> & lt; a href=" http://pan.baidu.com/s/1pKfVNwJ " rel==捌降取薄巴獠縩ofollow”目标的在百度网盘下载2 & lt;/a> & lt;/li>
downurl2=re.search (' & lt;/a> & lt;/li> & lt; li> & lt; a href=" https://www.yisu.com/zixun/(P 。+ ?)“rel==捌降取薄巴獠縩ofollow”目标的在百度网盘下载2 & lt;/a> & lt;/li>”, htmlcontent);
如果(downurl2):
downurl2=downurl2.group (“downurl2”);
打印”下载地址2:”downurl2;
file_object.write(“下载地址2:' + downurl2 + ' r ');
其他:
# file_error.write (url + ' r ');
打印”下载地址2不存在”;
file_error.write(标题+”下载地址2不存在r”);
file_error.write (' r ');
file_object.write (' r ');
打印“n”;
def getBooksUrl (url):
htmlcontent=getHtml (url);
# & lt; ul类=" cur-cat-list "祝辞& lt; a href=" https://www.yisu.com/books/438381.html " rel=巴獠縩ofollow”class=叭橥贰? lt;/ul> & lt;/div> & lt; !——结束#内容比;
url=re.findall (' & lt; a href=" https://www.yisu.com/zixun/(P





