本文实例讲述了Python3爬虫学习之MySQL数据库存储爬取的信息。分享给大家供大家参考,具体如下:
爬取到的数据为了更好地进行分析利用,而之前将爬取得数据存放在txt文件中后期处理起来会比较麻烦,很不方便,如果数据量比较大的情况下,查找更加麻烦,所以我们通常会把爬取的数据存储到数据库中便于后期分析利用。
这里,数据库选择MySQL,采用pymysql这个第三方库来处理python和MySQL数据库的存取,python连接MySQL数据库的配置信息
db_config={
“主机”:127.0.0.1,
“端口”:3306年,
“用户”:“根”,
“密码”:”,
“分贝”:“pytest”,
“字符集”:“use utf8”
}
之前
以爬取简书首页文章标题以及url为例,先分析抓取目标信息,

如上图、文章题目在一个标签中,且url (href)只含有后半部分,所以在存储的时候,最好把它补全。
mysql:新建一个数据库pytest,建立一张名为标题的表,表中字段分别为id (int自增),标题(varchar), url (varchar),如下:
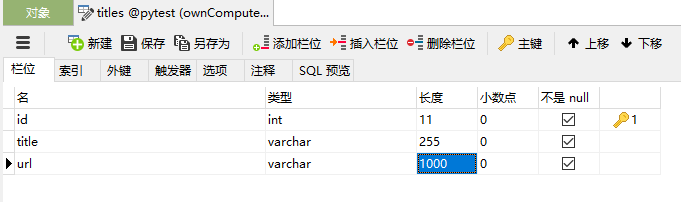
进行数据库操作的思路为:获得数据库连接(连接)→获得游标(光标)→执行sql语句(执行)→事物提交(提交)→关闭数据据库连接(关闭),具体代码实现如下:
# - * -编码:utf - 8 - *
从urllib导入请求
从bs4进口BeautifulSoup
进口pymysql
# mysql连接信息(字典形式)
db_config={
“主机”:127.0.0.1,
“端口”:3306年,
“用户”:“根”,
“密码”:”,
“分贝”:“pytest”,
“字符集”:“use utf8”
}
#获得数据库连接
连接=pymysql.connect (* * db_config)
#数据库配置,获得连接(参数方式)
#连接=pymysql.connect(主机=127.0.0.1,
#=3306港
#用户=?=" #密码,
# db=' pytest ',
# charset=use utf8)
url=r 'http://www.jianshu.com/'
#模拟浏览器头
头={
“用户代理”:“Mozilla/5.0 (Windows NT 10.0;AppleWebKit WOW64)/537.36 (KHTML,像壁虎)Chrome/55.0.2883.87 Safari/537.36”
}
请求页面=G肭?url,标题=标题)
page_info=request.urlopen(页面).read () .decode (“utf - 8”)
汤=BeautifulSoup (page_info html.parser)
url=汤。find_all (' a ', '标题')
试一试:
#获得数据库游标
光标connection.cursor ():
sql='插入标题(标题、url)值(% s % s) '
你的网址:
#执行sql语句
游标。执行(sql (u。字符串,r 'http://www.jianshu.com ' + u.attrs (“href”)))
#事务提交
connection.commit ()
最后:
#关闭数据库连接
connection.close ()
之前
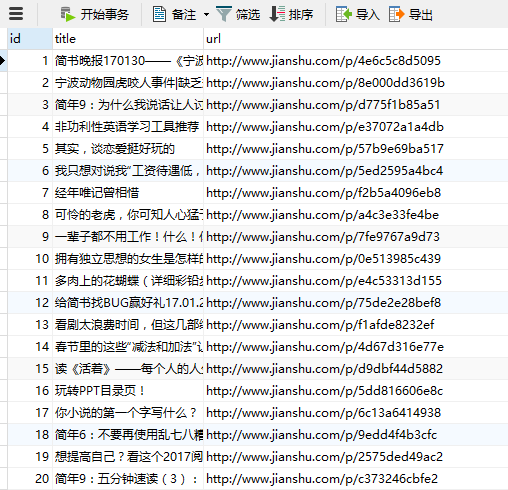
代码执行结果:
更多关于Python相关内容可查看本站专题:《Python套接字编程技巧总结》,《巨蟒正则表达式用法总结》,《Python数据结构与算法教程》、《Python函数使用技巧总结》,《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。





